



数量化Ⅱ類とは
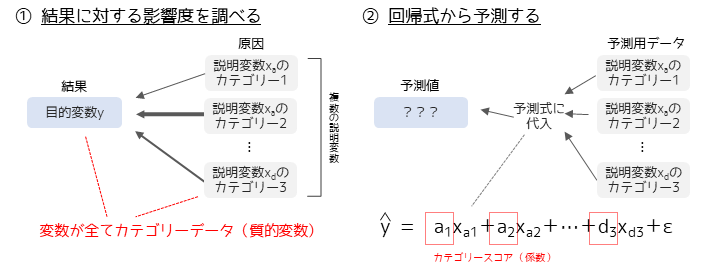
数量化Ⅱ類はカテゴリーデータ(質的変数)に対して行う多変量解析です.重回帰分析と同様に目的変数に対する説明変数の各カテゴリーの影響度や,作成した予測式に予測用データを代入することで結果の予測を行うことができます.
数量化とは林知己夫先生によって開発された手法で,数値でないデータを数値化する手法になります.数量化を行うことでアンケートの調査結果などの分析を行うことができます.
数量化Ⅱ類と同様にカテゴリーデータに対して行う分析である数量化Ⅲ類については,以下のページで解説しています.
数量化Ⅱ類の具体例
社会人20人に対してアンケートを取り,回答者には転職の希望度と仕事の悩みを5段階(1:当てはまらない-5:当てはまる)で回答してもらったとします.
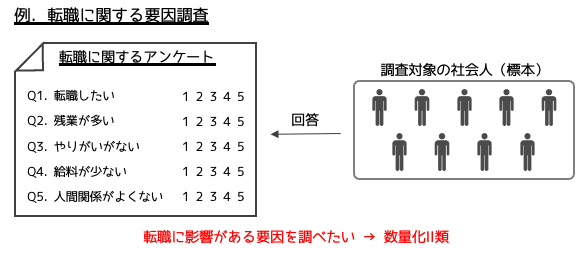
収集したデータは以下のようになります.

Q1の「転職したい」を目的変数として,その他の質問項目がどのように影響を与えてるかを数量化Ⅱ類を用いて調べます.数量化Ⅱ類の結果は主にカテゴリースコアやレンジ,偏相関係数で示されます.
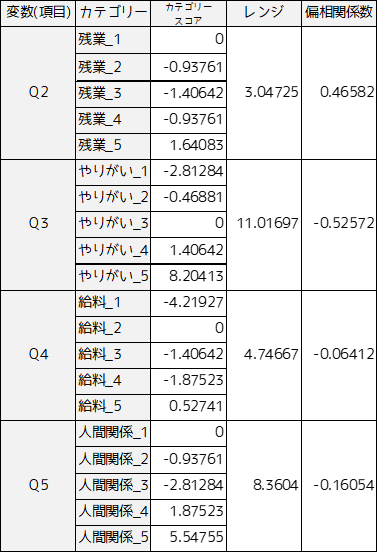
カテゴリースコアは作成した予測式の係数(重み)を意味します.
レンジは項目ごとのカテゴリースコアの最小値と最大値の差になります.レンジが大きいほどその項目の目的変数への影響度が大きいことを意味します.”Q3の仕事へのやりがい”は目的変数の”Q1の転職したい”に強く影響していることがわかります.
偏相関係数もレンジと同様に目的変数への影響度を示します.偏相関係数の絶対値が大きいほど目的変数に影響していることを示し,レンジと同様に”Q3の仕事へのやりがい”が”Q1の転職したい”に強く影響していることがわかります.
数量化Ⅱ類で作成した予測式自体の当てはまり度は相関比で表されます.相関比は0~1の間を取る指標で値が大きいほど予測式の当てはまりがよいことを意味します.一般的には相関比が0.5以上で,良い予測式と判断します.
数量化Ⅱ類の具体例(目的変数が2分類の場合)
目的変数が2分類の場合の数量化Ⅱ類について具体的に紹介します.目的変数が2分類の場合は,数量化Ⅱ類の結果を直感的に理解することができます.
社会人の副業に関連するデータを例に解説します(n=20).数量化Ⅱ類はカテゴリーデータに対して実行可能な解析手法であるため,以下のような名義尺度のデータに対しても行うことができます.

”副業の有無”を目的変数とした数量化Ⅱ類の実行結果は以下のようになります.
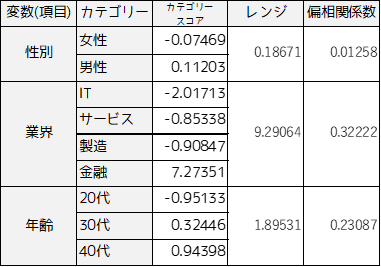
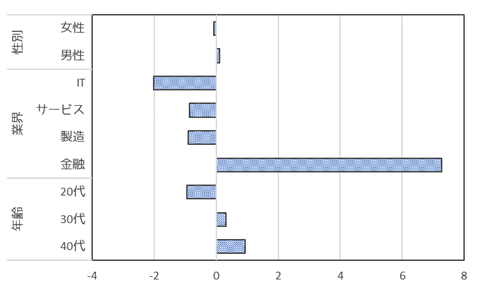
カテゴリースコアは上記のような横棒グラフで図示されることもあります.各変数内の横幅がレンジを示し,横幅が大きいほど目的変数に影響していることを示します.
目的変数が2分類の場合カテゴリースコアの解釈が容易で,例ではカテゴリースコアが負の値の場合は”副業あり”に影響を与えていることを示します.逆にカテゴリースコアが正の場合は”副業なし”に影響を与えていることを意味します.
”IT業界”や”20代”というカテゴリーは”副業あり”に強く影響しており,”金融業界”や”40代”は”副業なし”に強く影響していることがわかります.”性別”に関しては”副業の有無”にあまり影響がありません.これは偏回帰係数を見ても同様のことがわかります.
カテゴリースコアを用いて以下のように目的変数の予測式を作成することができます.

ある社会人の”性別”・”業界”・”年齢”のデータを予測式に代入することで,その社会人の副業有無を予測することができます.”性別”が女性の場合はXa1に1を,Xa2に0を代入します.代入して求めた値(サンプルスコア)が大きいほど,副業をしている可能性が低いと判断することができます.
数量化Ⅱ類の実行方法
数量化Ⅱ類は非常に複雑な計算が必要なため,手計算やExcelを用いて行うことは難しいです.日本の論文ではよく用いられますが世界的にはマイナーな手法なため,統計解析によく用いられるRやPythonでも私の調べた限りオープンソースのライブラリはなく自力でプログラムを作成する必要があります.AIによる出力は十分に注意してください.
統計解析アプリStaatAppでは数量化Ⅱ類が上記のように実行可能です.初めての方はほぼ全ての機能を無料で利用できるので,お気軽にダウンロードしてお使いください!
》StaatAppで行う数量化Ⅱ類
》統計解析アプリStaatAppとは
補足① カテゴリーデータの分析方法
数量化Ⅱ類のようにカテゴリーデータ(質的変数)の分析方法には,大きく2つの方法があります.数量化Ⅱ類は以下のダミー変数を利用した分析方法になります.
① ダミー変数
カテゴリーデータをダミー変数に変換することで,数量データとして扱うことができます.
例えば主成分分析で血液型というカテゴリーデータを扱いたい場合は,ダミー変数に変換して扱うことができます.重回帰分析においても一部の変数だけカテゴリーデータであった場合,ダミー変数に変換することで行うことができます.
② クロス集計表
カテゴリーデータの分析方法として最も一般的なのがクロス集計表になります.
多変量データをカテゴリ毎に度数で集計をして分析を行います.クロス集計表の分析方法としては,カイ二乗検定やオッズ比,コレスポンデンス分析があります.数量化Ⅱ類の事前分析としても,クロス集計表の分析はよく行われます.
補足② 多変量解析
数量化Ⅱ類のように目的変数と説明変数の関係性を調べる手法には,重回帰分析やロジスティック回帰分析があります.これらの手法の違いは各変数のデータの種類の違いになります.

例えば,目的変数がカテゴリーデータ(質的変数)で説明変数が量的変数の場合はロジスティック回帰分析がよく使われます.





