StaatAppでプロビット分析を行う方法を紹介します.SaatAppではCSVファイルやExcelファイルを読み込み,クリック操作だけでプロビット分析を行うことができます.
StaatAppについては以下をご覧ください.
アプリの基本操作
StaatApp基本操作(データの入出力など)は以下のページで解説しています.
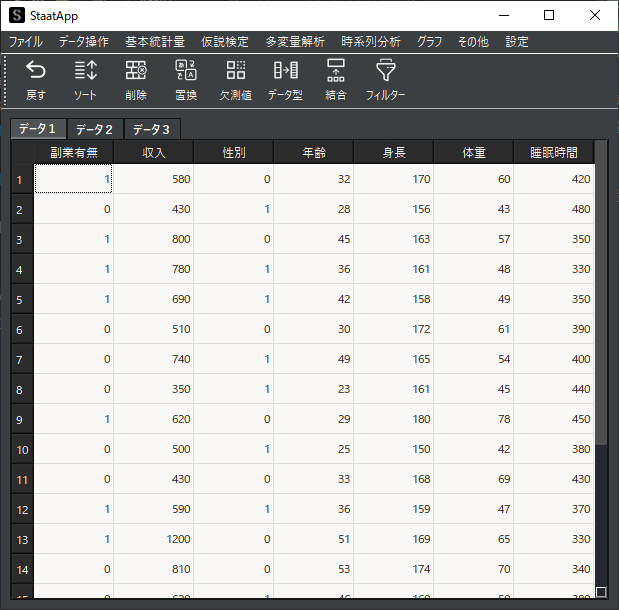
分析例として用いるサンプルデータは以下のようになります.”副業有無”と”性別”はダミー変数となっていますが,置換機能を用いてダミー変数に変換することも可能です.(副業有→”1″,女性→1″)
プロビット分析の実行(モデルの作成)
メニューバーから「多変量解析」→「回帰」→「プロビット分析」を選択してプロビット分析用ウィンドウを表示します.
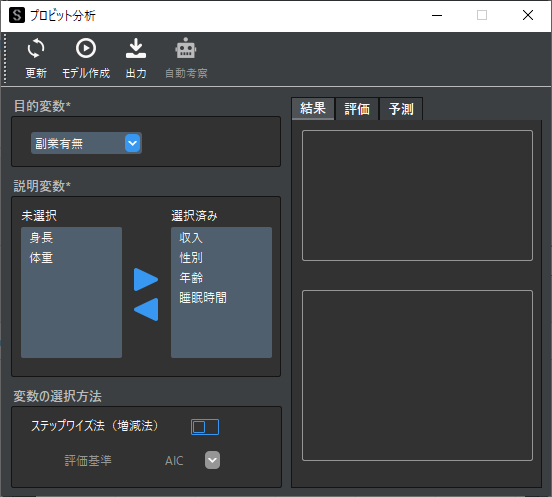
プロビット分析用ウィンドウが表示されたら,目的変数と説明変数の設定を行います.
ダミー変数を説明変数に選択する際は,多重共線性の問題を回避するために1列分を除いて選択します.
設定項目に入力が完了したら,ツールバーの「モデル作成」ボタンをクリックします.画面右側の「解析結果」にプロビット分析の結果が出力されます.
※ 説明変数に対してサンプルサイズが小さすぎると,モデルが作成できず結果は出力されません.
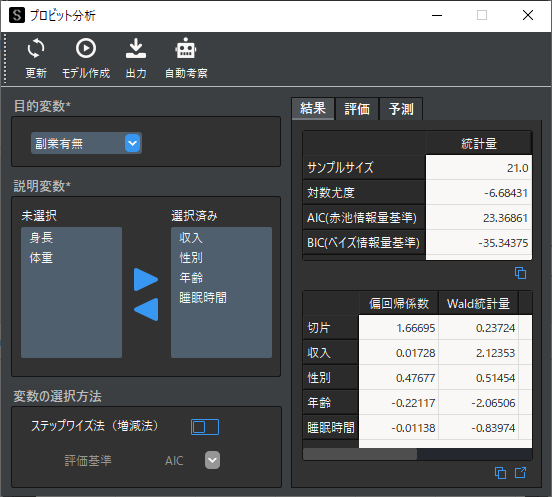
パラメータはポップアップボタンをクリックすることで以下のように表示することもできます.
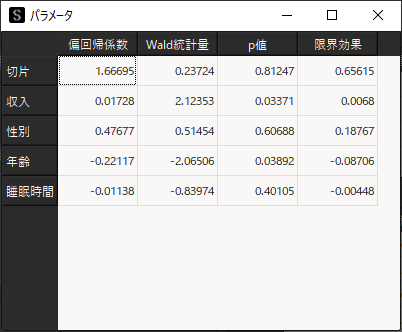
ステップワイズ法(応用)
選択した説明変数からステップワイズ法(増減法)で変数を自動選択する場合は,「変数の選択方法」のオプションで,ステップワイズ法をクリックしてから「モデルの作成」を行います.
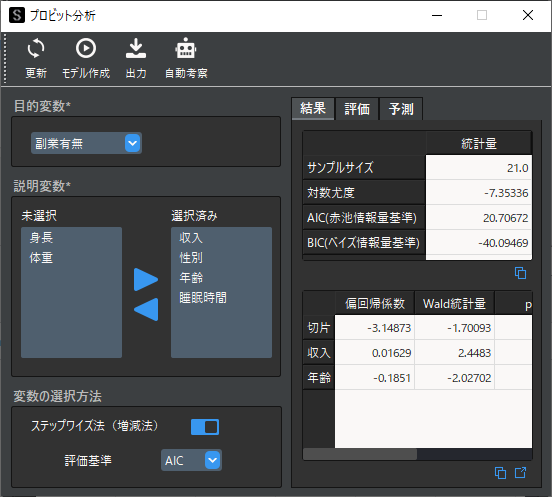
ステップワイズ法で使用するモデルの評価基準は,赤池情報量規準(AIC)もしくはベイズ情報量規準(BIC)から選択可能です
予測精度の評価(応用)
作成したモデルに対して,予測精度の評価を行う場合は「評価」タブで行います.事前にテストデータをモデル作成とは別のデータに入力しておき,「テストデータの選択」で対象のデータを選択します.
「算出」ボタンをクリックすると以下のように各評価指標と混合行列が表示されます.
※ テストデータには説明変数で選択した変数名(列名)を含む必要があります.
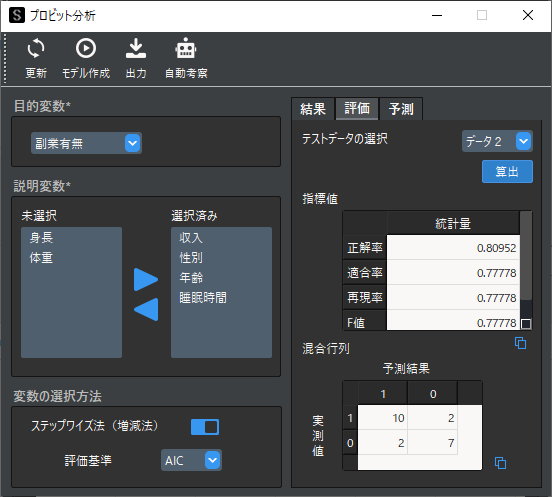
分類問題の評価指標と混合行列は以下のページで解説しています.
予測値の算出(応用)
作成したモデルを用いて予測値の算出を行います.「予測」タブから「予測用データの選択」を行い「算出」ボタンをクリックします.
※ 予測用データには説明変数で選択した変数名(列名)を含む必要があります.
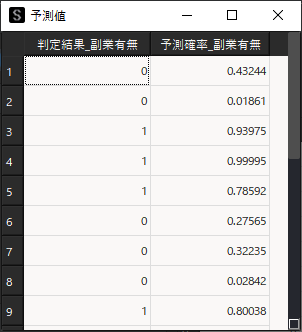
予測用データに対して,判定結果と予測確率が算出されます.
自動考察
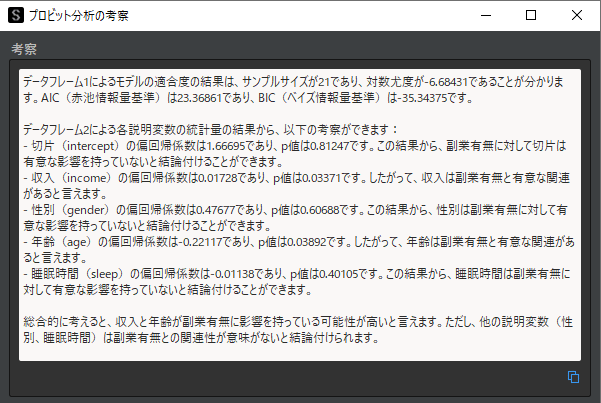
プロビット分析の解析結果について自動考察を行なうと,モデルの適合度と説明変数ごとの統計量について,以下のような考察結果を得ることができます.
補足① 結果の見方
プロビット分析の結果で見るべきポイントを解説します.
① 対数尤度
尤度(ゆうど)とは尤(もっと)もらしさを示す指標になります.対数尤度は値が大きいほど推定した回帰モデルの当てはまり良いことを意味します.
今回のような説明変数の組み合わせが1つの場合は見る必要はありません.説明変数の候補となるデータが他にもあり複数パターンで回帰モデルを推定した際に,対数尤度が最も大きい組み合わせが最も良い回帰モデルであると言えます.
② 偏回帰係数
偏回帰係数は0の場合は,その説明変数は推定した回帰モデルに影響を与えないということを意味します.値が正の場合は確率を上げる方向に,負の場合は確率を下げる方向に影響を与えます.
“収入”という説明変数は正の値であるため,収入が多いほど副業をしている確率が上がることを意味します.”年齢”は負の値であるので年齢が上がるほど副業をしている確率が下がることを意味します.
※ “切片”は回帰モデルの定数項になります.
③ Wald統計量
Wald統計量の絶対値が大きいほど,目的変数に影響を与えているということを意味します.
Wald統計量の絶対値が最も大きいのは”収入”であるので,年収の多さが副業の有無に最も影響を与えていると言えます.
④ p値
p値とは偏回帰係数のWald統計量についてのp値になります.p値が有意水準を下回ればその説明変数は有意な偏回帰係数であることが言えます.
統計学では一般的に有意水準α=0.05とすることが多いです.有意水準α=0.05とは,実際に関連性がない場合でも関連性が存在すると結論付けるリスクが5%であることを意味します.
有意水準α=0.05とすると,”収入”と”年齢”のみが統計的に有意であり目的変数に関連性があると言えます.
⑤ 限界効果
限界効果は偏回帰係数と同様に各説明変数の目的変数に対する影響度を示します.
分析例では性別の限界効果が0.187..であったので,”性別”が女性(=1)であった場合に,副業をしている確率が約19%増加することを意味します.
補足② 統計アプリStaatAppとは
StaatAppは計算仮定が複雑な解析手法を,誰でも手軽に素早く行なうことができるアプリです.StaatAppの詳細は以下のページをお読みください.

補足③ アプリの仕様について
アプリではPythonのScipyライブラリに含まれる,statsmodelsモジュールを用いてプロビット分析を行っています.statsmodelsはPythonで統計解析を行なう際に最も一般的なモジュールです
以下の公式ドキュメントに詳細な仕様が記載されています.