StaatAppを用いたデータクレンジング・操作方法について紹介します.本ページで紹介する機能は全てのプランで利用いただけます.
紹介する機能一覧
本ページではデータクレンジング・操作に用いる以下の機能を紹介します.
ツールバー機能
・ソート
・削除
・置換・変換
・欠測値の処理
・データ型の変換
・データの結合
・フィルター
メニューバー機能
・列名の変更
・ロングデータ ⇔ ワイドデータの変換
・差分・対数変換
・テストデータの作成
対象のデータ
以下のサンプルデータを対象に操作方法を紹介します.
| No. | 副業有無 | 収入 | 性別 | 年齢 | 身長 | 体重 | 睡眠時間 |
| 1 | 有 | 580 | 男性 | 32 | 170 | 60 | 420 |
| 2 | 無 | 430 | 女性 | 28 | 156 | 43 | 480 |
| 3 | 有 | 800 | 男性 | 45 | 163 | 57 | 350 |
| 4 | 有 | 780 | 女 | 36 | 161 | 48 | 330 |
| 5 | 有 | 690 | 女性 | 42 | 158 | 49 | 350 |
| 6 | |||||||
| 7 | 無 | 12000 | 女性 | 32 | 165 | 54 | 350 |
| 8 | 無 | 350 | 女性 | 23 | 161 | 45 | 440 |
| 9 | 有 | 620 | 男性 | 29 | 180 | 78 | 450 |
| 10 | 無 | 500 | 女性 | 150 | 42 | 380 | |
| 11 | 無 | 430 | 男 | 33 | 168 | 69 | 430 |
| 12 | 有 | 590 | 女性 | 36 | 159 | 47 | 370 |
| 13 | 有 | 1200 | 男性 | 51 | 169 | 65 | 330 |
| 14 | 無 | 810 | 男性 | 53 | 174 | 70 | 340 |
| 15 | 無 | 620 | 女性 | 380 | |||
| 16 | 無 | 430 | 女性 | 31 | 156 | 45 | 400 |
| 17 | 有 | 570 | 女性 | 39 | 164 | 52 | 350 |
| 18 | 無 | 460 | 男 | 28 | 170 | 59 | 430 |
| 19 | 有 | 620 | 男性 | 30 | 178 | 71 | 340 |
| 20 | 無 | 320 | 男性 | 25 | 167 | 62 | 410 |
| 21 | 無 | 430 | 女性 | 41 | 166 | 58 | 400 |
| 22 | 有 | 570 | 女性 | 39 | 164 | 52 | 350 |
複数列を対象にソート(並び替え)を行う
データ表示領域の列名部分をクリックすることでソートすることも可能ですが,数値データや複数列を基準として並び替えたい場合はツールバーの「ソート」機能を用います.
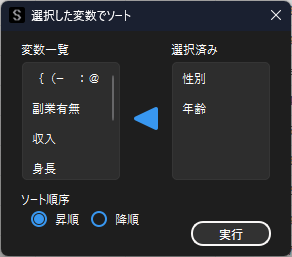
ダイアログから,並び替えの基準とする変数(列名)を選択します.上位の選択された変数ほど優先度が高くなります.例では年齢で並び替えたあとに性別で並び替えを行います.
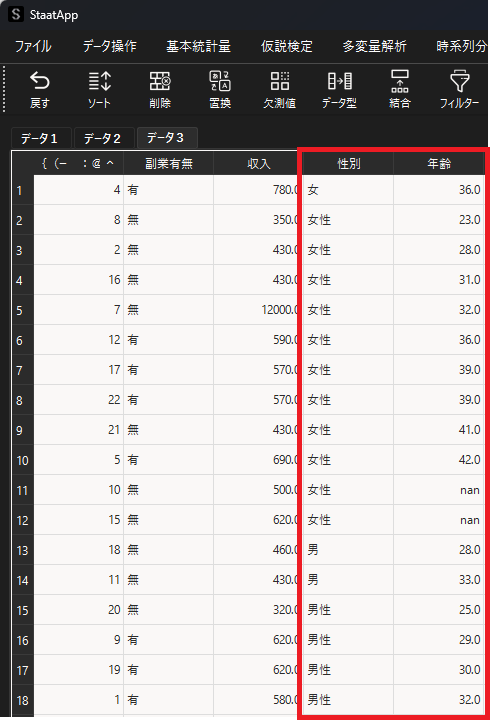
以下のようにデータを並び替えると,”性別”の列を見ると表記ゆれがあることがわかります.ソート機能では表記ゆれを簡単に発見できることも大きなメリットです.
列名をクリックすることでもソートを行うことが可能です.
不要な行または列を削除する
特定の行または列を削除する場合は「削除」機能を用います.
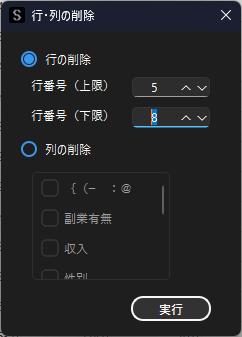
特定の行を削除したい場合は削除したい行番号を「行番号(上限)」に入力します.複数の行を一括で削除したい場合は,「行番号(上限)」に上側の行番号を,「行番号(下限)」に下側の行番号を入力します.
以下の設定では5行目から8行目が一括で削除されます.
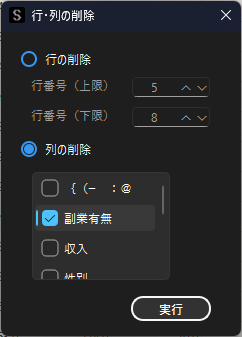
不要な列を削除した場合は,「列の削除」を選択して,削除したい列名にチェックを入れます.
任意の文字列・数値を置換する
特定の文字列から特定の文字列に値を変換したい場合は,「置換」機能を用います.
置換用ダイアログから置換前後の文字列を入力します.オプションの「完全に一致」ではセル内の文字列が完全に一致した場合のみ置換します.「半角英数字に変換」では全角英数字を自動で半角英数字に変換します.
例では”性別”列の表記ゆれを修正するために,”女”→”女性”に置換します.
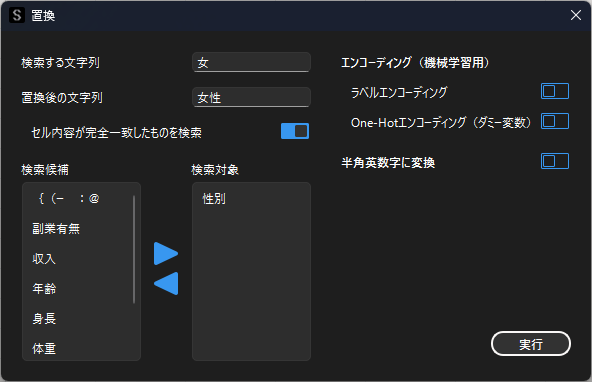
文字データからダミー変数を作成する場合は,「One-Hotエンコーディング」を選択して,変換対象の列を選択します.変換対処の列のカテゴリー数だけ新しい列が追加されます.
欠測値を削除・補完する
StaatAppでは空白データなどの欠測値を読み込ませた場合は,”nan”と表示されます.一括して”nan”の処理を行う場合は「欠測値」機能を用います.
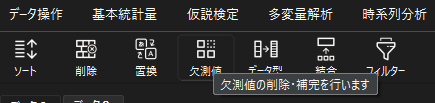
表示されたダイアログでは,画面左側で変数ごとの欠測値の数を確認することができます.
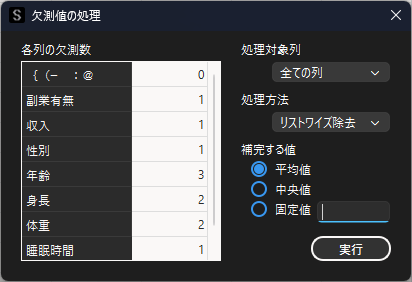
”年齢”列では欠測値が3つあることがわかります.欠測値の処理方法として以下の3つの方法が可能です.
・リストワイズ除去
・ペアワイズ除去
・補完
以下の設定では各変数の平均値で補完を行います.
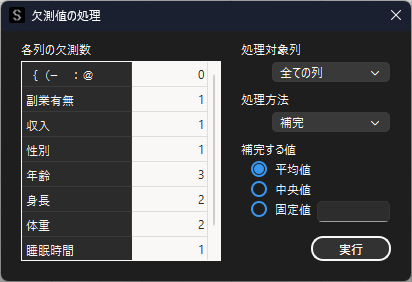
欠測値が平均値で補完されています.数値データでない”副業有無”や”性別”列は平均値を求めることができないため,”nan”のままとなります.
カテゴリーデータの欠測値に対しては,直接入力して値を変更もしくは除去することで対応します.
データ型を変換する
StaatAppでは「数値型」「文字列型」の2つのデータ型が存在します.
数値型:半角数字で入力された値.演算など順序尺度以上の統計解析が可能.
文字列型:半角英字・全角文字で入力された値.クロス集計表などのカテゴリー変数に対する統計解析が可能.
データ表示部分で値が左寄せされている列のデータ型は「文字列型」になります.逆に値が右寄せされている列は「数値型」になります.StaatAppではデータが読み込まれた時点で自動で判定されます.
「数値型」から「文字列型」もしくは,半角数字だけが入力されている列を「文字列型」から「数値型」に変換することは可能です.
ツールバーの「データ型」機能を用います.
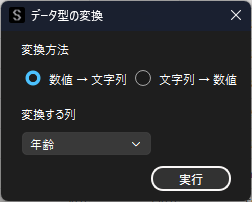
以下は”年齢”の列を「数値型」→「文字列型」に変換する例です.
※ 解析を実行した際に,データ型に関するエラーが発生する場合はこの機能を用いて変換してください.
2つのデータを結合する
2つのデータを結合したい場合は,「結合」機能を用います.
データ1とデータ2を結合したい場合は,以下のように設定します.
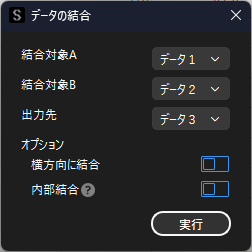
デフォルトではデータは縦方向に結合されます.同じ列名を持つデータを結合したい場合,サンプルサイズを増やしたい場合に用います.
オプションの「横方向に結合」を選択すると,同じ行同士でデータが結合されます.変数を加える場合や,解析後に出力した予測結果を元のデータに結合したい場合に用います.
特定の条件でデータを抽出する
特定の条件に一致するデータのみを抽出したい場合は,「フィルター」機能を用います.
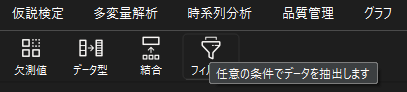
以下の例では”収入”列で,800より小さいデータのみを抽出します.
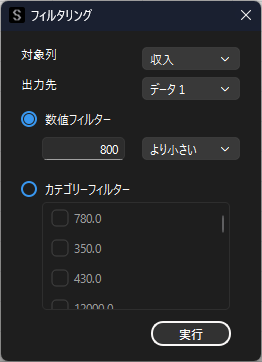
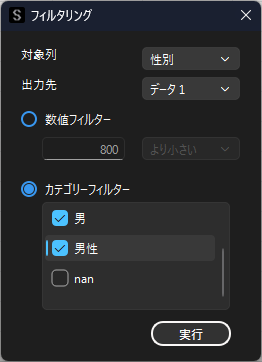
特定のカテゴリー(文字列)に一致するデータを抽出したい場合は,以下のように「カテゴリーフィルター」を選択して,抽出したいカテゴリーにチェックを入れます.
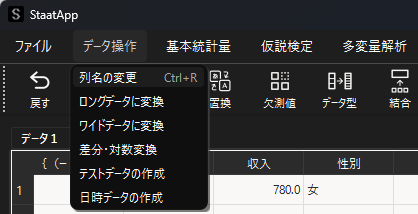
メニューバーのデータ操作機能の選択
メニューバーに設定されているデータ操作機能を用いる場合は,以下のように「データ操作」を選択して任意の機能を選択します.
列名(変数名)の変更
列名を変更する場合は,「列名の変更」機能を用います.「列名の変更」は「Ctrl + R」のショートカットキーでも実行可能です.
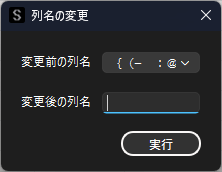
※ StaatAppでは同じデータ内に同じ列名が含まれると,正しく解析を実行できないので同じ列名が含まれる場合は,この機能を用いて変更してください.
ロングデータ ⇔ ワイドデータの変換
データ形式をロングデータからワイドデータに変換する場合は「ワイドデータに変換」,ワイドデータからロングデータに変換する場合は「ロングデータに変換」機能を用います.
変換機能の詳しい使い方やデータ形式については,以下のページをご覧ください.
差分・対数変換
特定の変数に対して,差分変換もしくは対数変換を行いたい場合は,「差分・対数変換」機能を用います.
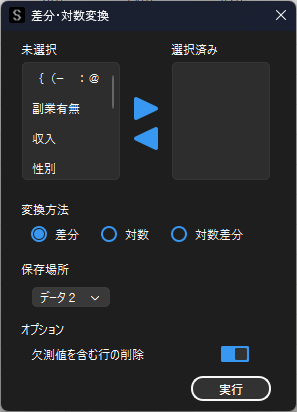
この機能は時系列分析を行う場合や,回帰分析を行う場合に有効です.
テストデータの作成
既存のデータからテストデータを作成したい場合は,「テストデータの作成」機能を用います.
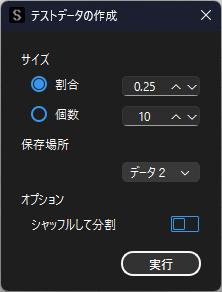
データの末尾から指定したサイズ分だけデータが分割されます.
オプションの「シャッフルして分割」を選択すると,データの末尾でなくランダムでレコードを選択して分割を行います.