



StaatAppで判別分析を行う方法を紹介します.SaatAppではCSVファイルやExcelファイルを読み込み,クリック操作だけで判別分析を行うことができます.
StaatAppについては以下をご覧ください.
アプリの基本操作
StaatApp基本操作(データの入出力など)は以下のページで解説しています.
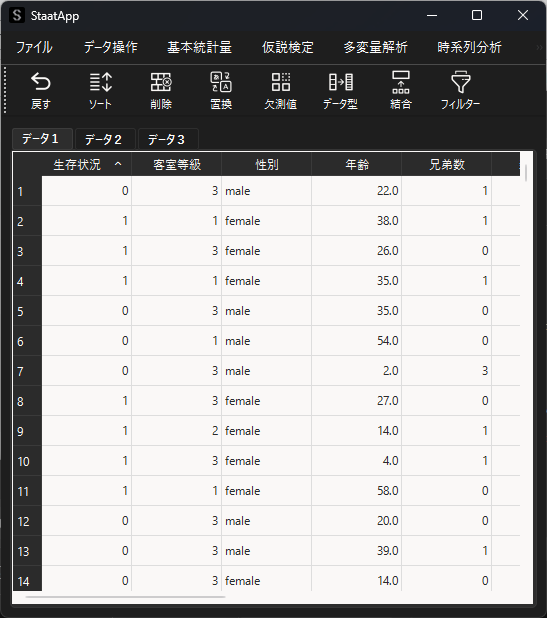
分析例として用いるサンプルデータ(タイタニック号データ)は以下のようになります.
判別分析の実行(モデルの作成)
メニューバーから「多変量解析」→「判別分析」を選択して判別分析用ウィンドウを表示します.
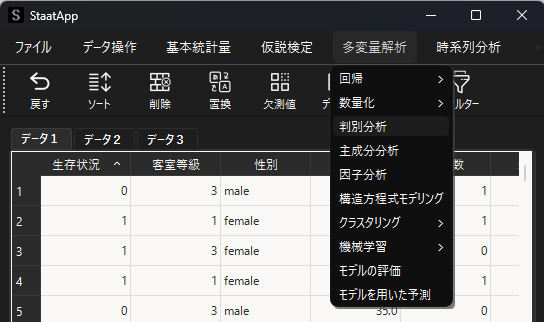
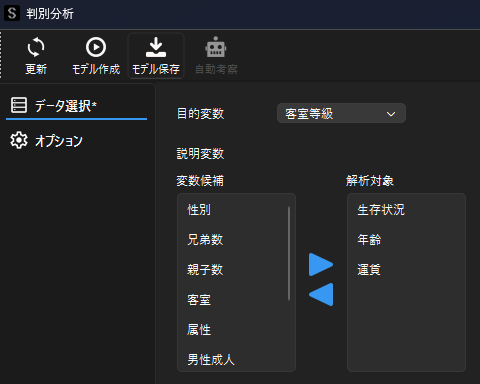
判別分析用ウィンドウが表示されたら,目的変数と説明変数の設定を行います.
ダミー変数を説明変数に選択する際は,多重共線性の問題を回避するために1列分を除いて選択します.
設定項目に入力が完了したら,ツールバーの「モデル作成」ボタンをクリックします.画面右側の「解析結果」に判別分析の結果が出力されます.
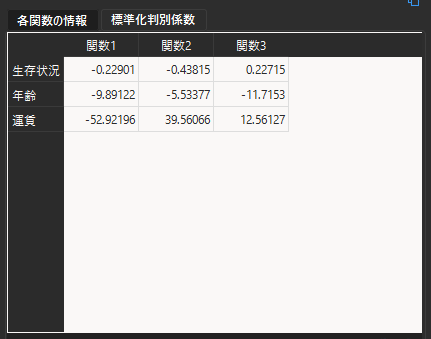
“正準相関”は正準判別相関係数を意味します.
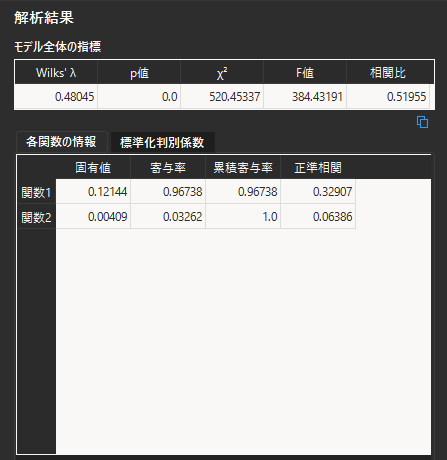
タブを切り替えることで,標準化判別係数の算出結果を表示することができます.
判別得点のプロット
オプション画面で,「判別得点のプロットの作成」をONにして,「モデル作成」を行うと以下のような関数1と関数2に対する判別得点のプロットを作成することができます.
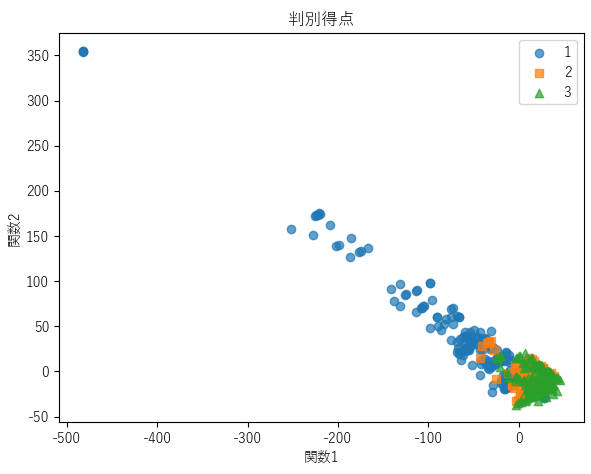
判別得点は目的変数のカテゴリー数が3以上の場合のみ作成できます.
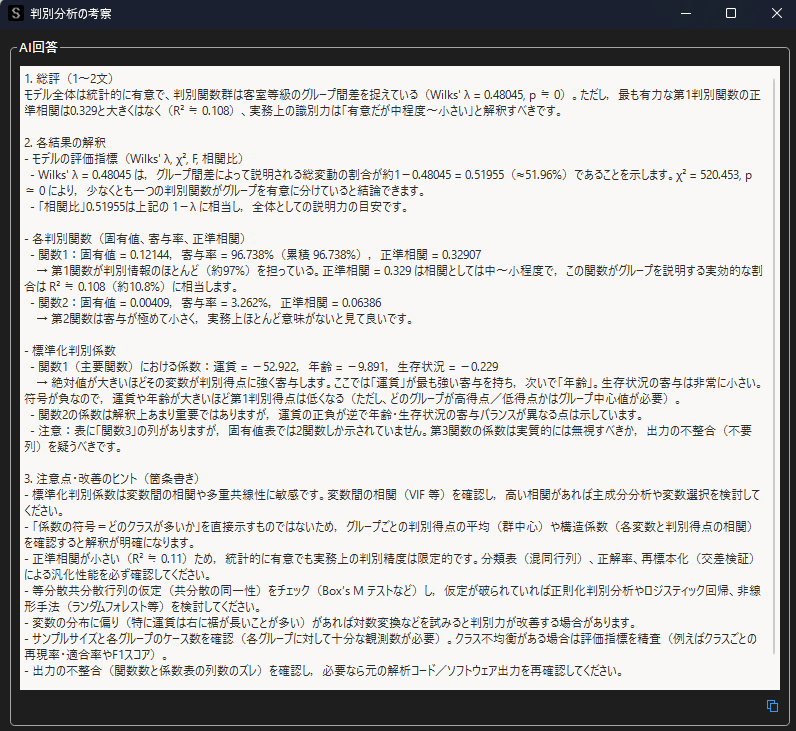
自動考察(プレミアムプラン限定)
判別分析の解析結果について自動考察を行なうと,各結果について以下のような考察・解説を得ることができます.
モデルの評価・予測(応用)
作成したモデルは保存することで,テストデータを用いた予測能力の評価や,予測用データを用いた目的変数の予測を行うことができます.
モデルを用いた評価・予測方法は以下のページで紹介しています.
補足① 統計アプリStaatAppとは
StaatAppは計算仮定が複雑な解析手法を,誰でも手軽に素早く行なうことができるアプリです.StaatAppの詳細は以下のページをお読みください.

補足② アプリの仕様について
アプリではPythonのscikit-learnライブラリを用いて判別分析を行っています.scikit-learnはPythonで統計解析・機械学習を行なう際に最も一般的なモジュールです
以下の公式ドキュメントに詳細な仕様が記載されています.





