



機械学習とは
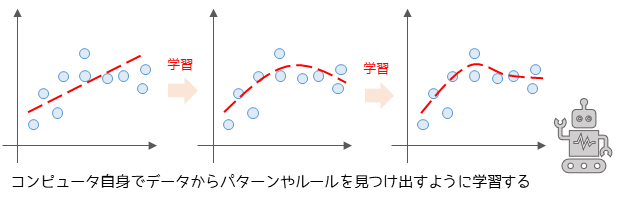
機械学習は,人間が持つ学習能力をコンピュータに模倣させることで,自動的にタスクを改善する能力を持たせる技術です.これにより,人間が手作業で行うのが困難な大量のデータの解析や,複雑な問題の解決をコンピュータに任せることが可能になります.
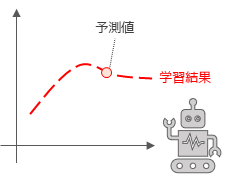
データ分析においては,学習結果を未知のデータを分類・予測するために活用されます.
人口知能・機械学習・深層学習の違い

機械学習は人口知能(AI, Artificial Intelligence)という技術・枠組みの一部になります.
人口知能は人間が行うような知的な作業をコンピュータが自動的に行う技術全般を指します.これには問題解決・学習・認識・理解・言語生成などが含まれます.人口知能の目標は,コンピュータに人間と同等の知的な動作をさせることになります.
深層学習(Deep Learning)は機械学習より具体的な技術で,機械学習の一部として位置づけられます.これは,人間の脳のニューロンの仕組みを模した「ニューラルネットワーク」を用いて,非常に複雑なパターンを学習します.深層学習は,大量のデータと高い計算能力が必要とされ,特に画像認識や自然言語処理など,複雑な問題の解決に利用されています.
統計解析と機械学習の違い
機械学習はデータ分析を行うためによく使用されます.データ分析で一般的に用いられるのは統計・統計解析ですが,これらの手法に明確な違いはありません.
ただし,それぞれに特徴はあるのでその特徴を説明します.
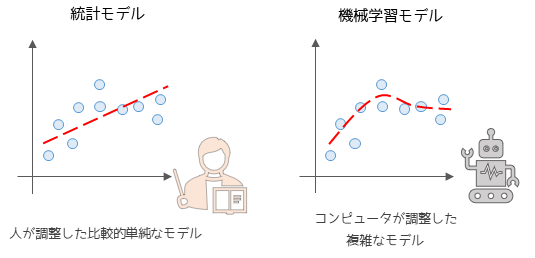
統計解析で用いられるモデルは統計モデルと言われ,よく知られている確率分布や比較的単純な関数にデータを当てはめてモデルを作成します.そのため,分析結果が解釈しやすいという利点がある一方で,人が想定していないデータ分布などには対応できずモデルの精度に限界が生じる場合があります.
機械学習モデルでは利用する関数の探索自体をコンピュータに任せるため,より複雑な関数・モデルとなります.そのため,計算過程や結果を完全に解釈することが難しい一方で,統計モデルより精度が高いモデルを作成できる可能性があります.
使用するデータ量に対しても違いがあり,統計モデルは比較的少ないデータに対してモデルを作成できますが,機械学習で精度の高いモデルを作成するためには大量のデータが必用となります.
機械学習の種類
機械学習には以下のような種類があります.
教師あり学習
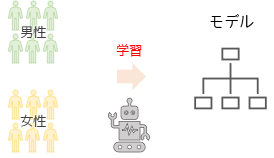
教師あり学習では,コンピュータに”正解”が付与されているデータを与えて,その”正解”を基準に学習を行いモデルを作成する方法です.モデルは与えられたデータから正しい結果を予測する方法を学習します.
学習結果であるモデルは,未知のデータの分類や予測に用いられます.
代表的な手法としては,決定木やロジスティック回帰分析,サポートベクターマシンなどがあります.深層学習も教師あり学習の一種になります.
教師なし学習
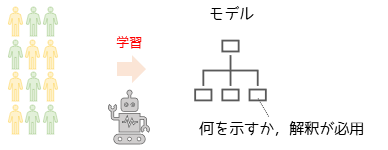
教師なし学習は,”正解”がないデータを用いてそのデータの構造やパターンを見つけ出す方法です.教師あり学習と異なり,学習結果が何を示すのかは分析者の解釈が必用になります.
代表的な手法としては,クラスター分析や主成分分析,One Class SVM(異常検知)などがあります.
強化学習

強化学習はエージェント(モデル)が環境と相互作用し,その結果として得られる報酬を最大化するように行動を学習する方法です.環境は状態に対して新しい状態と報酬を渡し,エージェントは渡された状態で行動行い,環境はその行動の評価結果としての報酬と次の状態をエージェントに渡す,というサイクルで最適な行動を学びます.
強化学習の一例としては,ゲームのAIがあります.例えば将棋のAIは,自身の行動が勝利にどのように影響するかを学習します.一手一手の選択が最終的な報酬(勝利)にどうつながるかを学び,最適な行動戦略を選択します.
代表的な手法としては,Q-LearningやPolicy Gradients,Actor-Critic methodsがあります.Q-Learningは囲碁AIのAlphaGoに用いられているアルゴリズムになります.
機械学習の手順
機械学習は一般的には以下の手順で行います.
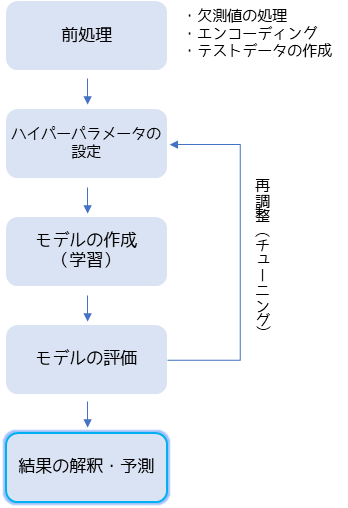
はじめにデータの前処理を行います.欠測値がある場合は補完や補正を行い,カテゴリーデータがある場合は置換などでエンコーディングを行います.テストデータは学習したモデルを評価するために作成します.機械学習ではデータを分割することで作成することが多いです.
教師あり学習ではターゲット変数を設定して,モデルを作成(学習)を行います.教師なし学習ではターゲット変数は設定せずに全て特徴量としてモデルを作成します.
モデルを作成したら教師あり学習では,テストデータと予測値を比較してモデルの評価を行います.教師なし学習では程よく分類されているかで評価を行います.モデルの精度が低い場合はハイパーパラメータの調整(パラメータチューニング)を行い,モデルの作成を行います.
モデルが十分な精度と判断できた場合,教師あり学習では予測・教師なし学習では結果の解釈を行います.
機械学習の用語
既にここまで説明でも使用しましたが,機械学習の分野での基本的な概念・用語を紹介します.
学習データ・テストデータ
学習データ(訓練データ)はモデルを作成するために用いるデータセットになります.テストデータはモデルの性能を評価するためのデータセットになります.
エンコーディング
文字データを数値データに変換することです.ダミー変数に変換するワンホットエンコーディングや,それぞれのカテゴリごとに整数に変換するラベルエンコーディングなどがあります.
特徴量
データの特性を表現する変数や属性のことで,モデルの入力値です.説明変数と表現することもあります.
ラベル
教師あり学習において,予測または分類を目指す変数のことです.ターゲット変数や目的変数と表現することもあります.
過学習
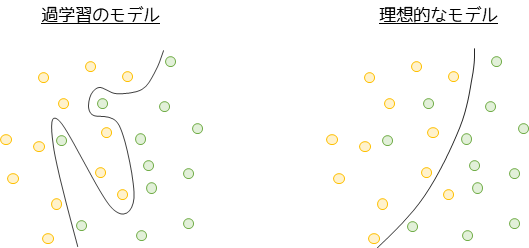
過学習はモデルが学習データに過度に適合してしまい,新しいデータに対する性能が低下する現象です.
ハイパーパラメータ
分析者が設定できるモデルのパラメータ(設定値).この値を調整することで,過学習をある程度防ぐことができます.
評価指標
モデルの性能を測るための指標で,問題の種類やビジネス上の要件によって選ばれます.精度、再現率、適合率、F1スコア、AUC-ROCなどがあります.
機械学習を行うならStaatApp
統計解析アプリStaatAppでは機械学習の代表的な手法である決定木を,プログラミングを行わずクリック操作だけで扱うことができます.発展的な手法であるランダムフォレストや勾配ブースティング決定木にも対応してます.
初めての方はほぼ全ての機能を無料で利用できるので,お気軽にダウンロードしてお使いください!
》統計解析アプリStaatApp
》Staatappを用いた決定木






