



決定木とは
決定木(Decision Tree)とは機械学習の1つのアルゴリズムで,データの分類・予測を行うために使用されます.決定木はある条件に基づきデータを2分割して,さらにその結果に基づきデータを分割するという作業を繰り返すアルゴリズムです.
具体的に,決定木を用いて社会人集団のデータから副業の有無を分類する例を考えてみます.(判定内容等は全て仮定です)
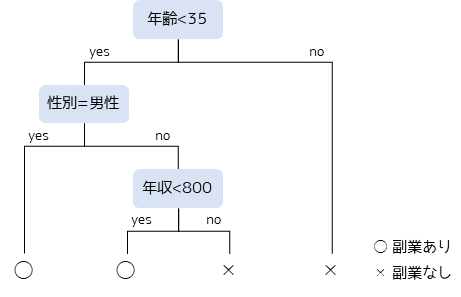
まず,各社会人の”年齢”という数値から副業有無の可能性を分類します.年齢が若いほど,特に35歳未満であれば副業を行っている可能性が高い場合,図のようなしきい値で判定が行われます.
次に年齢が35歳未満で性別が”男性”であった場合,最終的に”副業あり”と判定します.また,年齢が35歳以上もしくは,35歳未満かつ女性かつ年収が800万以上の人は”副業なし”と判定します.
このように決定木では特徴量(属性や数値)をもとに分岐を繰り返して,データの分類・予測を行います.分岐条件を可視化した際の図を反対にすると”木”のように見えることから,決定木と呼ばれています.
決定木で用いる単語
決定木では以下の用語がよく使用されます.
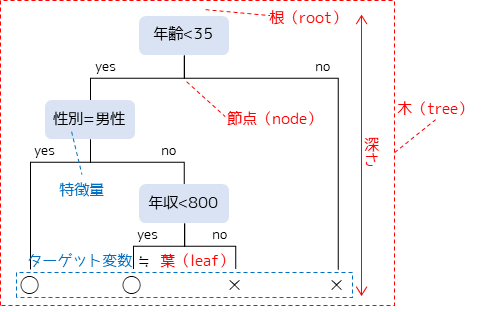
木(tree):分割基準を可視化した構造全体を意味します.
根(root):決定木の最上部で,分割前のデータセット全体を意味します.
接点(node):特定の基準に対する分岐点を意味します.”ノード”という言い方もよくされます.
葉(leaf):分岐の最終的な結果を意味します.
深さ:根から葉までの距離,木の大きさを意味します.
特徴量:機械学習共通の用語で,分類や回帰の条件となる変数(説明変数)を意味します.
ターゲット変数:機械学習共通の用語で,分類・予測の対象となる変数(目的変数)を意味します.決定木では”葉”と同意になります.
決定木のメリット・デメリット
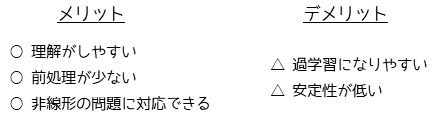
決定木の最大のメリットは理解のしやすさになります.分析結果の木構造が可視化できるため,どのような過程で結果が出力されたのかを直感的に判断することができます.
前処理が少ないことも大きなメリットになります.統計解析ではデータが正規分布に従うことを前提として手法が多いですが,決定木では正規化を行う必要がなく,数値データからカテゴリーデータまで様々なデータに対して用いることができます.外れ値に対しても強いため,外れ値の処理も不要となります.
決定木の最大のデメリットは過学習(overfitting)になりやすいことです.過学習とはモデルが学習データに過剰に適合して,テストデータ(未知のデータ)に対する予測精度が低下することです.
また,学習データのわずかな変化でも決定木の構造が大きく変化することがあるため,安定性が低いとったデメリットもあります.
分類問題と回帰問題
決定木には分類問題と回帰問題の2パターンがあります.これらは予測したいターゲット変数の種類によって区別されます.
分類問題
ターゲット変数がカテゴリーデータである場合,つまり入力データがどのカテゴリーに属するかを予測する場合になります.例えば,特定のメールが「スパム」か「スパムでない」かを判別する2値分類や,特定の人の音楽の好みを「ポップ」「ロック」「クラシック」「ジャズ」から予測する多クラス分類問題があります.
分類問題における決定木は,ある特徴量に基づいてデータを分割し,最終的には各葉が1つのカテゴリーに対応します.
回帰問題
ターゲット変数が数値データである場合になります.例えば,特定の人の属性(性別・年齢・居住地など)から年収を予測するケースが考えられます.
回帰問題における決定木でも,特徴量に基づいてデータを分割しますが,最終的に各葉は予測する数値(連続値)を表します.通常,その葉に属するデータポイントのターゲット変数の平均値が予測値となります.
決定木と過学習
決定木の最大のデメリットである過学習について解説します.2値分類問題における過学習のイメージは以下のようになります.
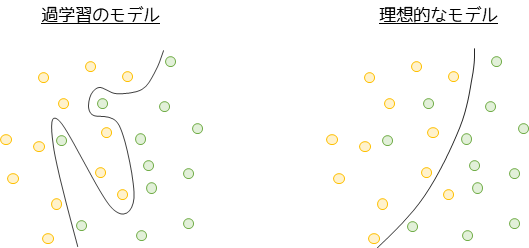
過学習は学習データに対して過剰に適合することを意味します.過学習のモデルは学習データの細かい特徴にも適合するために,明らかに違和感のある境界線となります.このようなモデルは一般的に,未知のデータに対すする予測性能(汎化性能)が低くなってしまいます.
逆に理想的なモデルは程よく学習データに適合して,汎化性能が高いことを意味します.
決定木において過学習を防ぐには,ハイパーパラメータというモデルの挙動を制御する設定値を調整します(ハイパーパラメータチューニング).例えば,葉に属する最小のサンプル数や葉の最大数を設定します.過学習を防ぐ際に特に有効と知られているのが,木の深さになります.木の深さを制限することで決定木の分岐回数が減り過学習を防ぐことができます.
汎化性能は学習データで作成したモデルに対して,テストデータ当てはめることで調べることができます.決定木において汎化性能は正解率(分類問題)や決定係数(回帰問題)など様々な指標値を用いて評価することができます.
決定木の発展的な手法

決定木の発展的な手法であるランダムフォレストは,決定木を複数作成してその結果の平均または多数決で分類・推測を行います.複数の決定木は学習データや特徴量に対して無作為抽出行い,様々な条件で作成します.
ランダムフォレストでは多数の決定木を用いることで,1本の木では判断が不十分であった部分を補うことを目指します.
ランダムフォレストのさらに発展的な手法が勾配ブースティング決定木です.
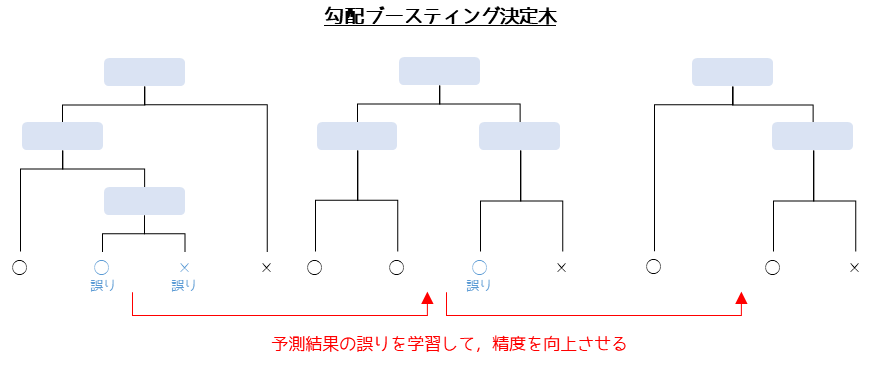
勾配ブースティング決定木(Gradient Boosting Decision Trees, GBDT)では,まず1つの決定木を作成して,予測値と真の値との差(残差)を比較します.次にその残差を考慮して新しい決定木を作成します.これを繰り返すことで,最終的に予測精度を高めることを目指します.
勾配ブースティング決定木は,決定木やランダムフォレストと比較しても予測精度が高いと言われています.実際にデータサイエンス・機械学習の競技プラットフォームであるKaggleでは,非常に多くの参加者から使用されており使いやすいさという観点も考慮すると,2023年現在で最強の手法であると言えます.
ただし,勾配ブースティング決定木にもデメリットは存在して,ランダムフォレストでは並列に決定木を作成(バギング)しますが,勾配ブースティング決定木では直列に決定木を作成(ブースティング)するため,計算効率があまりよくありません.そのため,大規模なデータセットに対しては時間がかかる可能性があります.
また,「決定木」 → 「ランダムフォレスト」 → 「勾配ブースティング決定木」の順でモデルが複雑であるためハイパーパラメータの調整が難しくなります.加えて,ランダムフォレスト・勾配ブースティング決定木の木構造は可視化することができません.
決定木を用いた分析を行う方法
決定木は計算方法が複雑なため,Excelなどの手計算で行うことは難しいです.基本的にはRやPythonなどのプログラミング言語を用いて行う必要があります.
統計解析アプリStaatAppでは決定木を,プログラミングを行わずクリック操作だけで扱うことができます.発展的な手法であるランダムフォレストや勾配ブースティング決定木にも対応してます.
初めての方はほぼ全ての機能を無料で利用できるので,お気軽にダウンロードしてお使いください!
》統計解析アプリStaatApp
》Staatappを用いた決定木






