PythonのライブラリであるPandasを用いたデータクレンジングの方法を紹介します.日本語が記述されたデータ(CSVファイル)を例に紹介します.
データクレンジングとは
データクレンジングとはデータ分析を行いやすくする,正しい分析結果を得るためにデータをきれいにする(クレンジング)ことです.
既存データに対してデータクレンジングを行わないまま分析を行った場合,誤った分析結果になる可能性があります.
例えば以下のように,入力規則・表記方法がばらばらのデータがあるとします.データクレンジングを行わないまま分析を行った場合,3人の被験者は同じ回答内容であるはずなのに異なる結果として分析される,もしくは計算自体が上手くできないといった問題が発生します.
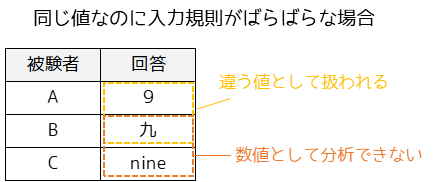
データクレンジングでは具体的に,データの削除や置換といった作業を行います.先程のデータ(ダーティデータ)を置換することで,正しい分析が可能なデータを得ることができます.

サンプルデータと読み込み
具体的にデータクレンジングの方法を解説するために,欠測値や外れ値,表記ゆれを含んだダーティデータを使用します.
「ダーティデータ.csv」というファイル名で保存して,以下ような記述でPandasのデータフレームとして読み込ませます.Pythonで読み込むせるデータ形式(CSVファイル)の作り方はこちら.
# ライブラリのインポート
import chardet
import pandas as pd
# データの読み込み
with open("ダーティデータ.csv", 'rb') as f:
binary = f.read()
d = chardet.detect(binary)
if d["encoding"] == "utf-8":
enco = "utf-8"
elif d["encoding"] == "UTF-8-SIG":
enco = "utf_8_sig"
else:
enco = "SHIFT-JIS"
df_workers = pd.read_csv("ダーティデータ.csv", encoding=enco)※ Excelを用いてデータを作成したことを想定して冗長な記述となっています.(文字コードを自動判定して,日本語が文字化けしないための記述です)
読み込ませたデータは以下のようになります.データフレームでは欠測値は”NaN”で示されます.
No. 副業有無 収入 性別 年齢 身長 体重 睡眠時間
0 1 有 580.0 男性 32.0 170 60.0 420.0
1 2 無 430.0 女性 28.0 156 43.0 480.0
2 3 有 800.0 男性 45.0 163 57.0 350.0
3 4 有 780.0 女 36.0 161 48.0 330.0
4 5 有 690.0 女性 42.0 158 49.0 350.0
5 6 NaN NaN NaN NaN NaN NaN NaN
6 7 無 3200.0 女性 32.0 165 54.0 350.0
7 8 無 350.0 女性 23.0 161 45.0 440.0
8 9 有 620.0 男性 29.0 180 78.0 450.0
9 10 無 500.0 女性 NaN 150 42.0 380.0
10 11 無 430.0 男 33.0 168 69.0 430.0
11 12 有 590.0 女性 36.0 159 47.0 370.0
12 13 有 1200.0 男性 51.0 169 65.0 330.0
13 14 無 810.0 男性 53.0 174 70.0 340.0
14 15 無 620.0 女性 NaN NaN NaN 380.0
15 16 無 430.0 女性 31.0 156 45.0 400.0
16 17 有 570.0 女性 39.0 164 52.0 350.0
17 18 無 460.0 男 28.0 170 59.0 430.0
18 19 有 620.0 男性 30.0 178 71.0 340.0
19 20 無 320.0 男性 25.0 167 62.0 410.0
20 21 無 430.0 女性 41.0 166 58.0 400.0
21 22 有 570.0 女性 39.0 164 52.0 350.0データクレンジングの手順
以下の手順でデータクレンジングを行います.必ずこの順番で行う必要はありませんが,個人的にはだいたいこの順序で行っています.
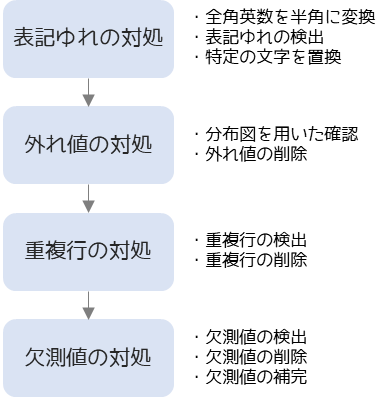
ここから紹介する方法や用いているライブラリに関してもあくまでも自己流のやり方になります.紹介する方法以外にも簡単に記述する方法などはあることにご留意ください.
また,関数の引数やデータフレームの基本操作などは適宜調べてみてください.
表記ゆれの対処(全角英数文字→半角)
全角英数字では数値として扱うことができないため,半角英数字に変換する必要があります.変換するためのライブラリとして,jaconvを用います.
# ライブラリのインポート
import jaconv
# 全角文字を半角に変換する関数を定義
def conv(data, column):
# データ型をstr型に変換
dtype = data[column].dtypes
data[column] = data[column].astype(str)
list = data[column].values.tolist()
new_list = []
for li in list:
li = jaconv.z2h(li, digit=True, ascii=True, kana=True)
new_list.append(li)
data[column] = new_list
# float型に変換
if "object" != dtype:
data[column] = data[column].astype(float)
return data[column]
# 処理したいカラム名の指定
columns = ["身長"]
# 定義した関数を用いて変換の実行
for column in columns:
conv(df_workers, column)データフレームに対して一括で変換することはできないため,変換処理を関数化して(4-23行目)指定した列ごとにループ処理で変換を行います.
サンプルデータでは”身長”列に全角数字が含まれていたため,指定して変換を行います.
jaconvで変換する関数ではstr型でないとエラーになるため,float型などはデータ型の変換を行ってから実行します.
No. 副業有無 収入 性別 年齢 身長 体重 睡眠時間
0 1 有 580.0 男性 32.0 170 60.0 420.0
1 2 無 430.0 女性 28.0 156 43.0 480.0
2 3 有 800.0 男性 45.0 163 57.0 350.0
3 4 有 780.0 女 36.0 161 48.0 330.0
4 5 有 690.0 女性 42.0 158 49.0 350.0実行した結果,No.1の身長の”170”が半角文字に変換されています.
表記ゆれの対処
表記ゆれの有無を検出するために,対象の列に対して重複を取り除いた一意のリストを作成します.”性別”の列に対して表記ゆれが無いかを確認します.
# 表記ゆれの検出
u_list = df_workers["性別"].unique()
print("一意のリスト\n", u_list)
-->
一意のリスト
['男性' '女性' '女' nan '男']出力結果から”男性”と”男”,”女性”と”女”の2つの表記ゆれがあることがわかります.
表記ゆれの対処方法として置換を行います.データフレームに対してはreplace関数を用いることで置換を行うことができます.
# 特定の列の値の置換
df_workers.replace({"性別": {"女": "女性", "男": "男性"}}, inplace=True)replace関数では特定の列の値を置換する場合は,辞書型で引数を記述します.実行結果は以下のようになります.
No. 副業有無 収入 性別 年齢 身長 体重 睡眠時間
0 1 有 580.0 男性 32.0 170 60.0 420.0
1 2 無 430.0 女性 28.0 156 43.0 480.0
2 3 有 800.0 男性 45.0 163 57.0 350.0
3 4 有 780.0 女性 36.0 161 48.0 330.0
4 5 有 690.0 女性 42.0 158 49.0 350.0
5 6 NaN NaN NaN NaN NaN NaN NaN
6 7 無 3200.0 女性 32.0 165 54.0 350.0
7 8 無 350.0 女性 23.0 161 45.0 440.0
8 9 有 620.0 男性 29.0 180 78.0 450.0
9 10 無 500.0 女性 NaN 150 42.0 380.0
10 11 無 430.0 男性 33.0 168 69.0 430.0
11 12 有 590.0 女性 36.0 159 47.0 370.0
12 13 有 1200.0 男性 51.0 169 65.0 330.0
13 14 無 810.0 男性 53.0 174 70.0 340.0
14 15 無 620.0 女性 NaN NaN NaN 380.0
15 16 無 430.0 女性 31.0 156 45.0 400.0
16 17 有 570.0 女性 39.0 164 52.0 350.0
17 18 無 460.0 男性 28.0 170 59.0 430.0
18 19 有 620.0 男性 30.0 178 71.0 340.0
19 20 無 320.0 男性 25.0 167 62.0 410.0
20 21 無 430.0 女性 41.0 166 58.0 400.0
21 22 有 570.0 女性 39.0 164 52.0 350.0外れ値の対処
分布図を作成することで外れ値の確認を行います.分布図としてはストリッププロットや散布図など様々なグラフがありますが,ここでは最も基本的なヒストグラムで紹介します.
matplotlibを用いてヒストグラムを作成します.サンプルデータの”収入”に外れ値が無いかを調べます.
# ライブラリのインポート
import matplotlib.pyplot as plt
# ヒストグラムの作成
plt.hist(df_workers["収入"], bins=20)
plt.show()以下のようなヒストグラムが作成されます.ヒストグラムが見えづらい場合は,ビン数(棒の幅)を変更して再度作成します.
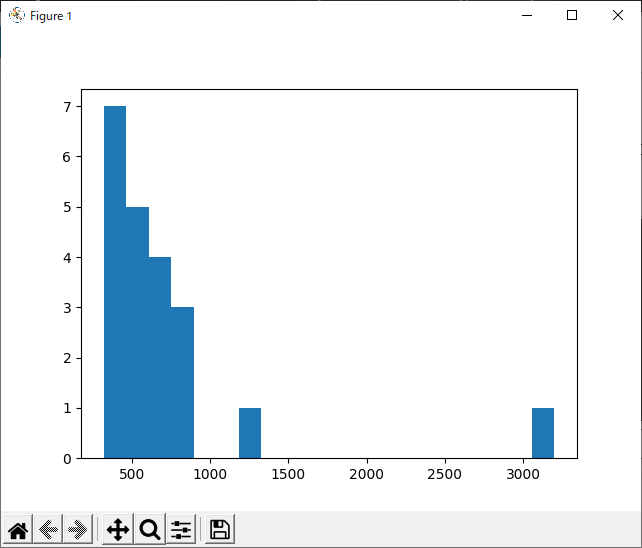
明らかに集団から離れているデータ(No.7)があることがわかります.しかし,収入が飛び抜けて高い人は現実にも実在して明らかに誤ったデータとは言えないので今回は外れ値として削除しないこととします.
外れ値として削除する場合は,drop関数などで行ごとデータを削除します.
重複データの対処
重複データの有無を確認するために,重複データの抽出を行います.
データフレームではduplicated関数を用いて重複データの抽出・削除を行うことができます.
# 重複行の抽出
subset = ["副業有無", "収入", "性別", "年齢", "身長", "体重", "睡眠時間"]
print("重複した行\n", df_workers[df_workers.duplicated(subset=subset)])
-->
重複した行
No. 副業有無 収入 性別 年齢 身長 体重 睡眠時間
21 22 有 570.0 女性 39.0 164 52.0 350.02行目で重複行として判定の対象とする列名を指定します.全ての列を判定対象とする場合は必要ありません.
サンプルデータではNo.22のデータが重複していることがわかります.(No17と重複しています)
重複行の削除はdrop_duplicated関数を用いて行います.
# 重複行の削除
df_workers = df_workers.drop_duplicates(subset=subset)以下のように重複した行が削除されます.
No. 副業有無 収入 性別 年齢 身長 体重 睡眠時間
0 1 有 580.0 男性 32.0 170 60.0 420.0
1 2 無 430.0 女性 28.0 156 43.0 480.0
2 3 有 800.0 男性 45.0 163 57.0 350.0
3 4 有 780.0 女性 36.0 161 48.0 330.0
4 5 有 690.0 女性 42.0 158 49.0 350.0
5 6 NaN NaN NaN NaN NaN NaN NaN
6 7 無 3200.0 女性 32.0 165 54.0 350.0
7 8 無 350.0 女性 23.0 161 45.0 440.0
8 9 有 620.0 男性 29.0 180 78.0 450.0
9 10 無 500.0 女性 NaN 150 42.0 380.0
10 11 無 430.0 男性 33.0 168 69.0 430.0
11 12 有 590.0 女性 36.0 159 47.0 370.0
12 13 有 1200.0 男性 51.0 169 65.0 330.0
13 14 無 810.0 男性 53.0 174 70.0 340.0
14 15 無 620.0 女性 NaN NaN NaN 380.0
15 16 無 430.0 女性 31.0 156 45.0 400.0
16 17 有 570.0 女性 39.0 164 52.0 350.0
17 18 無 460.0 男性 28.0 170 59.0 430.0
18 19 有 620.0 男性 30.0 178 71.0 340.0
19 20 無 320.0 男性 25.0 167 62.0 410.0
20 21 無 430.0 女性 41.0 166 58.0 400.0欠測値への対処
データフレームの欠測値の検出は,isnull関数を用いることで実行可能です.
# 欠測値の確認
print(df_workers.isnull().sum())
-->
No. 0
副業有無 1
収入 1
性別 1
年齢 3
身長 2
体重 2
睡眠時間 1
dtype: int64各列の欠測値(NaN)の数が算出されます.
欠測値に対しては,除去もしくは補完する2つの方法があります.
① 欠測値を除去する方法
データフレームの欠測値を除去するためには,dropna関数を用います.
全ての値(列)が欠測値である場合にデータ(行)を除去するペアワイズ除去と,どれかの値が欠測値である場合にデータを除去するリストワイズ除去の記述例はそれぞれ以下になります.
# ペアワイズ除去
df_workers.dropna(how="all")
# リストワイズ除去
df_workers.dropna(how="any")リストワイズ除去の実行結果は以下になります.欠測値(NaN)が全て取り除かれました.
No. 副業有無 収入 性別 年齢 身長 体重 睡眠時間
0 1 有 580.0 男性 32.0 170 60.0 420.0
1 2 無 430.0 女性 28.0 156 43.0 480.0
2 3 有 800.0 男性 45.0 163 57.0 350.0
3 4 有 780.0 女性 36.0 161 48.0 330.0
4 5 有 690.0 女性 42.0 158 49.0 350.0
6 7 無 3200.0 女性 32.0 165 54.0 350.0
7 8 無 350.0 女性 23.0 161 45.0 440.0
8 9 有 620.0 男性 29.0 180 78.0 450.0
10 11 無 430.0 男性 33.0 168 69.0 430.0
11 12 有 590.0 女性 36.0 159 47.0 370.0
12 13 有 1200.0 男性 51.0 169 65.0 330.0
13 14 無 810.0 男性 53.0 174 70.0 340.0
15 16 無 430.0 女性 31.0 156 45.0 400.0
16 17 有 570.0 女性 39.0 164 52.0 350.0
17 18 無 460.0 男性 28.0 170 59.0 430.0
18 19 有 620.0 男性 30.0 178 71.0 340.0
19 20 無 320.0 男性 25.0 167 62.0 410.0
20 21 無 430.0 女性 41.0 166 58.0 400.0② 欠測値を補完する方法
データフレームの欠測値を補完するためには,fillna関数を用います.
どのような値で補完するかはデータ分析者次第になりますが,よく使われる値である該当列ごとの平均値で補完する記述例は以下のようになります.
df_workers.fillna(df_workers.mean())特定の値(例えば”0”)や中央値を指定して補完することも可能です.カテゴリーデータは平均値が存在しないため,欠測値のままとなります.
No. 副業有無 収入 性別 年齢 身長 体重 睡眠時間
0 1 有 580.0 男性 32.000000 170.0 60.000000 420.0
1 2 無 430.0 女性 28.000000 156.0 43.000000 480.0
2 3 有 800.0 男性 45.000000 163.0 57.000000 350.0
3 4 有 780.0 女性 36.000000 161.0 48.000000 330.0
4 5 有 690.0 女性 42.000000 158.0 49.000000 350.0
5 6 NaN 721.5 NaN 35.222222 165.0 56.526316 386.5
6 7 無 3200.0 女性 32.000000 165.0 54.000000 350.0
7 8 無 350.0 女性 23.000000 161.0 45.000000 440.0
8 9 有 620.0 男性 29.000000 180.0 78.000000 450.0
9 10 無 500.0 女性 35.222222 150.0 42.000000 380.0
10 11 無 430.0 男性 33.000000 168.0 69.000000 430.0
11 12 有 590.0 女性 36.000000 159.0 47.000000 370.0
12 13 有 1200.0 男性 51.000000 169.0 65.000000 330.0
13 14 無 810.0 男性 53.000000 174.0 70.000000 340.0
14 15 無 620.0 女性 35.222222 165.0 56.526316 380.0
15 16 無 430.0 女性 31.000000 156.0 45.000000 400.0
16 17 有 570.0 女性 39.000000 164.0 52.000000 350.0
17 18 無 460.0 男性 28.000000 170.0 59.000000 430.0
18 19 有 620.0 男性 30.000000 178.0 71.000000 340.0
19 20 無 320.0 男性 25.000000 167.0 62.000000 410.0
20 21 無 430.0 女性 41.000000 166.0 58.000000 400.0補足① PyCharmを用いた実行環境の構築
Pythonを初めて使う方や,自分のPCにPython・PyCharmが入っていない方は以下のページで解説している手順で実行環境の構築を行ってください.
初めて触る方にもわかりやすいようにPyCharmを用いた手順となっています.
本ページでは,”pandas”や”matplotlib”,”jaconv”というライブラリを使用します.インストール方法が分からない方は,ライブラリのインストールを参考にしてください.
》実行環境の構築方法【Pycharm使用】
》ライブラリのインストール方法【Pycharm使用】
補足② Pythonで読み込むデータの作成方法
Pythonで扱うCSVファイルの作成方法は以下のページで解説しています.