Pythonで統計解析を行うためのCSVファイルの作り方について紹介します.
文字化けしてしまった際の対応方法についても解説しています.
CSVファイルとは
CSVファイルのCSVとは,Comma Separated Valueの略でカンマ(,)で区切った値が格納されたファイルです.

表形式のデータであるため,PythonやExcelで読み込んで使用することができます.
同じ表形式のデータとしてはExcelファイルがありますが,CSVファイルはExcelのような豊富な情報(セル内の計算式やフォントなど)を保持しておらず単純なデータになります.
単純なデータのためメモ帳などのテキストエディタで編集することも可能で,Pythonの入力データとして最も使われます.
Excelを用いたCSVファイルの作り方
Pythonで扱うためのCSVファイルの作り方について解説します.
メモ帳などでも作成することができますが,Excelを用いた方が列操作などができデータの加工が簡単なのでおすすめです.
① データの入力・加工
Excelで以下のようにデータを入力します.
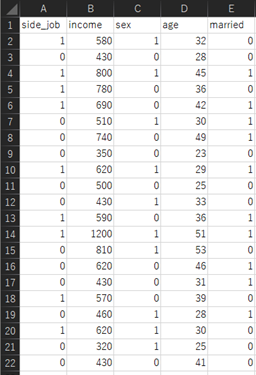
Excelにデータ入力する際のポイントが以下の4つになります.誤った形式でデータを入力するとPythonでプログラムを実行した際のエラーが起きてしまうため必ず守るようにしてください.
① A1のセルからデータを入力する(1行目は項目名)
② 空白のセルを作らない(全ての項目のデータが無い場合は除外する)
③ 値は半角英数字で入力する.スペースは’_’などで代用する.
④ ‘はい/いいえ’のようなデータはダミー変数に置換する(’1/0’など)
データ入力・加工の基本については以下のページで解説しています.
② CSVファイルの出力
データを入力したらCSVファイルとして出力します.
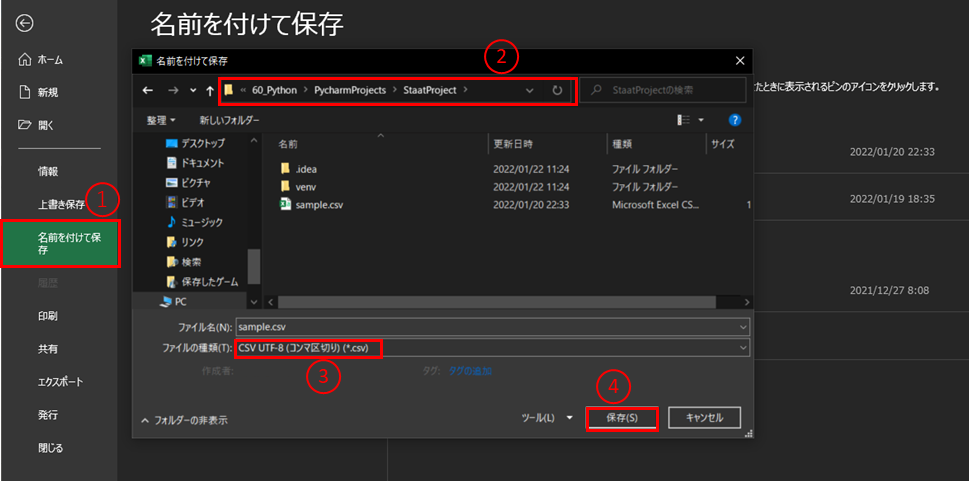
Excel画面左上の「ファイル」から「名前を付けて保存」を選択します.
「参照」を選択してファイルの保存先を選択します.保存場所は,統計解析を行うプロジェクトフォルダの直下に配置してください.別の場所に置いてしまうとPythonで,読み込ませるのが大変になります.
保存場所を指定したら,「ファイルの種類(T)」から「CSV UTF-8(コンマ区切り)(*.csv)」を選択します.
任意のファイル名を入力して「保存(S)」ボタンを選択します.
保存する際に以下のような警告が出た場合は,「OK」を選択してください.(データを入力したシートのみが保存されます.)

以上が,Pythonで用いるCSVデータの作成方法です.
CSVファイルの読み込み方
作成したCSVファイルの読み込み方について解説します.
PythonではPandasというライブラリを用いて,CSVファイルをデータフレーム(表形式)として読み込みます.
# ライブラリのインポート
import pandas as pd
# データの読み込み
df_workers = pd.read_csv("sample.csv")Pandasのread_csv関数を用いて簡単に読み込むことができます.
PandasとはExcelのように表形式のデータを操作するためのライブラリです.Pandasに含まれる関数を用いることで,特定の列の値だけ取り出したり複数の表を結合するなどの操作が可能です.
Pythonで統計解析を行う際は,CSVファイルの作成→データフレームの作成→対象のデータに対して解析を行うが一般的な方法になります.
補足① Pythonを用いた統計解析
本サイトではPythonを用いた統計解析について,プログラムの記述例や結果の見方について解説しています.
補足② CSVファイルの文字コード
CSVファイルを作成して,データフレームとして読み込む際に文字化けやエラーが起きることがあります.
原因はCSVファイルとPythonのデフォルトの文字コードの違いになります.read_csv関数ではデフォルトがutf-8として読み込みます.(文字コードとはコンピュータが文字を識別するための規則です)
CSVファイルの文字コードがSHIFT-JISであった場合,文字コードの違いから文字化けを起こしてしまいます.CSVファイルの文字コードがSHIFT-JISの場合は以下のようにオプションで指定します.
df_workers= pd.read_csv("sample.csv",encoding="SHIFT-JIS")上記の方法以外にも,サクラエディタのようなソフトでCSVファイルの文字コードを変換するという方法もあります.
おまけとして文字コードを気にせずにCSVファイルを読み込む方法について紹介します.(StaatAppで使用してるコードです)
# ライブラリのインポート
import pandas as pd
import chardet
# CSVファイルの読み込み
with open("sample.csv", 'rb') as f:
binary = f.read()
d = chardet.detect(binary)
if d["encoding"] == "utf-8":
enco = "utf-8"
elif d["encoding"] == "UTF-8-SIG":
enco = "utf_8_sig"
else:
enco = "SHIFT-JIS"
df_workers = pd.read_csv("sample.csv", encoding=enco)文字コードを判定するchardetライブラリとIF文を組み合わせることで,CSVファイルの文字コードに合わせてデータフレームを作成します.