



コレスポンデンス分析(Multiple Correspondence Analysis)の具体的な計算方法について,Pythonのmcaライブラリを用いて解説します.
初めてPythonを使う方でも実行できるような手順解説になっています.補足事項として,結果の見方や扱うデータの前提条件についても解説しています.
例題の設定
コレスポンデンス分析を用いた統計解析を説明するために,以下の例題・データを用います.
「20代から40代の男女に副業の有無についてアンケート調査を行いました(複数回答あり).回答結果から回答者の属性と副業の種類の関係性についてコレスポンデンス分析を用いて評価します.」
| 回答者 | 副業 |
|---|---|
| 30代女性 | ブログ |
| 30代男性 | SNS |
| 20代男性 | ポイ活 |
| 20代男性 | 仮想通貨 |
| 20代男性 | デリバリー |
| 20代女性 | SNS |
| 30代女性 | ライター |
| 30代女性 | デリバリー |
| 30代女性 | SNS |
| 20代男性 | せどり |
| 30代男性 | ライター |
| 40代男性 | SNS |
| 30代女性 | ブログ |
| 30代男性 | デリバリー |
| 30代女性 | ポイ活 |
| 20代女性 | ポイ活 |
| 30代男性 | 動画制作 |
| 30代男性 | 仮想通貨 |
| 40代女性 | ポイ活 |
| 40代男性 | デリバリー |
| 30代男性 | 動画制作 |
| 40代女性 | ブログ |
| 20代女性 | デリバリー |
| 20代男性 | デリバリー |
| 20代女性 | ブログ |
| 20代女性 | SNS |
| 40代男性 | デリバリー |
| 20代女性 | ポイ活 |
| 20代男性 | デリバリー |
| 30代女性 | ブログ |
| 40代男性 | ブログ |
| 40代男性 | ポイ活 |
| 20代男性 | 仮想通貨 |
| 30代男性 | SNS |
| 30代女性 | SNS |
| 40代男性 | 仮想通貨 |
| 30代女性 | ライター |
| 20代女性 | 仮想通貨 |
| 20代女性 | ブログ |
| 20代女性 | 動画制作 |
| 30代女性 | ポイ活 |
| 30代女性 | ブログ |
| 20代女性 | ブログ |
| 20代男性 | デリバリー |
| 40代男性 | ライター |
| 30代女性 | ブログ |
| 30代男性 | デリバリー |
| 30代女性 | ブログ |
| 40代女性 | ライター |
| 40代男性 | ライター |
| 20代女性 | ライター |
| 30代女性 | ブログ |
| 30代女性 | せどり |
| 30代男性 | ライター |
| 40代男性 | ライター |
| 20代男性 | 仮想通貨 |
| 30代男性 | ポイ活 |
| 20代男性 | デリバリー |
| 20代男性 | SNS |
| 30代女性 | ブログ |
| 40代女性 | ライター |
| 30代女性 | ブログ |
| 20代男性 | SNS |
| 30代男性 | ポイ活 |
| 20代男性 | デリバリー |
| 30代男性 | ブログ |
| 30代女性 | ブログ |
| 20代女性 | ブログ |
| 40代男性 | 仮想通貨 |
| 40代男性 | デリバリー |
| 20代男性 | 仮想通貨 |
| 30代女性 | ポイ活 |
| 30代男性 | 仮想通貨 |
| 40代男性 | ポイ活 |
| 30代女性 | ブログ |
| 20代女性 | 動画制作 |
| 20代男性 | ポイ活 |
| 40代男性 | ブログ |
| 20代男性 | ブログ |
| 30代女性 | ポイ活 |
| 30代女性 | 仮想通貨 |
| 20代男性 | デリバリー |
| 30代男性 | ポイ活 |
| 30代女性 | ポイ活 |
| 40代女性 | ポイ活 |
| 30代女性 | ポイ活 |
| 30代女性 | ライター |
| 40代男性 | ポイ活 |
| 20代男性 | ポイ活 |
| 30代男性 | 仮想通貨 |
| 30代男性 | ブログ |
| 40代女性 | ポイ活 |
| 30代男性 | 仮想通貨 |
| 30代女性 | ポイ活 |
| 20代女性 | ブログ |
| 40代女性 | ブログ |
| 30代女性 | ブログ |
| 20代女性 | ブログ |
| 30代男性 | デリバリー |
| 30代男性 | ブログ |
| 20代女性 | SNS |
| 40代女性 | ポイ活 |
| 30代女性 | SNS |
| 30代男性 | SNS |
| 20代男性 | 動画制作 |
| 20代男性 | デリバリー |
| 30代男性 | ライター |
| 20代女性 | ライター |
| 30代男性 | SNS |
| 40代男性 | 仮想通貨 |
| 30代男性 | 動画制作 |
| 40代女性 | ブログ |
| 20代男性 | 動画制作 |
| 40代男性 | 仮想通貨 |
| 20代男性 | SNS |
| 20代女性 | ブログ |
| 30代男性 | 動画制作 |
| 20代女性 | ライター |
| 40代女性 | ブログ |
| 20代男性 | 動画制作 |
| 20代男性 | ライター |
| 30代女性 | ライター |
| 20代男性 | ブログ |
| 20代男性 | せどり |
| 40代女性 | ブログ |
| 30代女性 | SNS |
| 30代男性 | ポイ活 |
| 30代女性 | ブログ |
| 30代男性 | ポイ活 |
| 30代男性 | 仮想通貨 |
| 30代男性 | 仮想通貨 |
| 30代男性 | ライター |
| 40代男性 | デリバリー |
| 20代男性 | デリバリー |
| 20代男性 | デリバリー |
| 20代男性 | ブログ |
| 30代男性 | ポイ活 |
| 30代男性 | 動画制作 |
| 40代女性 | ブログ |
| 40代女性 | ブログ |
| 20代男性 | SNS |
| 20代男性 | ブログ |
| 20代男性 | 仮想通貨 |
| 20代女性 | ポイ活 |
| 30代女性 | デリバリー |
| 20代男性 | 仮想通貨 |
| 20代女性 | ライター |
| 20代女性 | SNS |
| 30代女性 | ポイ活 |
| 20代男性 | 仮想通貨 |
| 40代女性 | ライター |
| 20代男性 | 動画制作 |
| 30代男性 | ポイ活 |
| 20代女性 | ブログ |
| 30代女性 | ブログ |
| 30代男性 | デリバリー |
| 30代女性 | ブログ |
| 30代男性 | SNS |
| 30代女性 | せどり |
| 30代女性 | ブログ |
| 20代男性 | 動画制作 |
| 20代女性 | ライター |
| 40代男性 | SNS |
| 20代男性 | 動画制作 |
| 20代女性 | 動画制作 |
| 20代男性 | 仮想通貨 |
| 20代男性 | ライター |
| 30代男性 | せどり |
| 30代女性 | ライター |
| 30代男性 | ブログ |
| 20代男性 | ブログ |
| 30代男性 | デリバリー |
| 20代男性 | デリバリー |
| 20代男性 | デリバリー |
| 40代男性 | せどり |
| 40代男性 | ポイ活 |
| 30代女性 | ライター |
| 30代女性 | ポイ活 |
| 20代男性 | デリバリー |
| 30代男性 | 動画制作 |
| 40代男性 | せどり |
| 20代男性 | ブログ |
| 20代女性 | SNS |
| 40代女性 | SNS |
| 30代女性 | ブログ |
| 20代男性 | 仮想通貨 |
| 20代男性 | せどり |
| 20代男性 | デリバリー |
| 30代女性 | ブログ |
| 30代男性 | 動画制作 |
| 20代男性 | せどり |
| 20代女性 | 仮想通貨 |
| 40代男性 | デリバリー |
| 40代女性 | ブログ |
| 20代男性 | SNS |
| 30代女性 | ライター |
| 20代男性 | 仮想通貨 |
| 20代男性 | ライター |
| 40代女性 | ライター |
| 20代女性 | デリバリー |
| 40代男性 | 仮想通貨 |
| 20代男性 | ポイ活 |
| 20代女性 | せどり |
| 20代男性 | 仮想通貨 |
| 30代男性 | 仮想通貨 |
| 20代男性 | デリバリー |
| 20代女性 | ポイ活 |
| 30代女性 | せどり |
| 40代男性 | デリバリー |
| 20代女性 | ライター |
| 20代男性 | 動画制作 |
| 20代男性 | デリバリー |
| 40代女性 | ブログ |
| 20代女性 | ブログ |
| 20代男性 | デリバリー |
| 20代男性 | デリバリー |
| 30代男性 | SNS |
| 20代女性 | せどり |
| 20代女性 | ライター |
| 30代男性 | 動画制作 |
| 40代女性 | ポイ活 |
| 30代男性 | デリバリー |
| 20代男性 | せどり |
| 30代男性 | ブログ |
| 20代男性 | SNS |
| 30代女性 | 仮想通貨 |
| 30代男性 | せどり |
| 30代男性 | 仮想通貨 |
| 20代女性 | ライター |
| 20代女性 | ブログ |
| 30代男性 | ライター |
| 30代男性 | デリバリー |
| 30代男性 | デリバリー |
| 30代女性 | ポイ活 |
| 40代男性 | デリバリー |
| 20代男性 | 動画制作 |
| 20代女性 | ポイ活 |
| 30代女性 | ブログ |
| 40代男性 | 仮想通貨 |
| 20代男性 | SNS |
| 20代男性 | デリバリー |
| 30代女性 | ブログ |
| 20代男性 | 動画制作 |
| 20代男性 | ライター |
| 20代女性 | ブログ |
| 30代男性 | ブログ |
| 30代男性 | 仮想通貨 |
| 40代女性 | SNS |
| 40代男性 | デリバリー |
| 20代男性 | SNS |
| 40代男性 | デリバリー |
| 40代男性 | ブログ |
| 20代男性 | 仮想通貨 |
| 20代男性 | デリバリー |
| 30代女性 | SNS |
| 20代男性 | 仮想通貨 |
| 40代男性 | デリバリー |
| 30代男性 | ポイ活 |
| 20代男性 | ライター |
| 20代女性 | ブログ |
| 30代女性 | ライター |
| 30代女性 | 動画制作 |
| 40代男性 | デリバリー |
| 30代男性 | 仮想通貨 |
| 20代男性 | せどり |
| 20代男性 | ポイ活 |
| 40代男性 | デリバリー |
| 30代女性 | SNS |
| 40代男性 | ブログ |
| 30代女性 | ライター |
| 40代女性 | ブログ |
| 20代男性 | 動画制作 |
| 20代男性 | デリバリー |
| 30代男性 | デリバリー |
| 30代女性 | ポイ活 |
| 20代女性 | ポイ活 |
| 40代女性 | ブログ |
| 30代男性 | ポイ活 |
| 20代男性 | 動画制作 |
| 20代男性 | 動画制作 |
| 30代男性 | せどり |
| 30代男性 | ポイ活 |
| 40代女性 | ブログ |
| 30代女性 | デリバリー |
| 40代男性 | デリバリー |
| 30代女性 | SNS |
| 40代女性 | せどり |
| 30代男性 | ライター |
| 20代女性 | ブログ |
| 30代男性 | ライター |
| 40代男性 | デリバリー |
| 30代男性 | 仮想通貨 |
| 40代男性 | デリバリー |
| 40代女性 | SNS |
| 20代男性 | デリバリー |
| 30代男性 | デリバリー |
| 40代男性 | デリバリー |
| 30代女性 | ライター |
| 30代女性 | せどり |
| 20代男性 | SNS |
| 20代男性 | デリバリー |
| 20代女性 | SNS |
| 20代女性 | ポイ活 |
| 20代男性 | デリバリー |
| 20代女性 | SNS |
| 30代女性 | 仮想通貨 |
| 20代女性 | SNS |
| 20代女性 | せどり |
| 30代女性 | ポイ活 |
| 20代男性 | ブログ |
| 30代女性 | ブログ |
Pythonで読み込むせるデータ形式(CSVファイル)の作り方はこちら.
プログラムの作成
Pythonを用いてプログラムの作成をします.
コレスポンデンス分析に必要な記述例は以下になります.(結果の出力方法については次の章で解説しています.)
# ライブラリのインポート
import mca
import matplotlib.pyplot as plt
import japanize_matplotlib
import pandas as pd
import chardet
# CSVファイルの読み込み
with open("correspondence.csv", 'rb') as f:
binary = f.read()
d = chardet.detect(binary)
if d["encoding"] == "utf-8":
enco = "utf-8"
elif d["encoding"] == "UTF-8-SIG":
enco = "utf_8_sig"
else:
enco = "SHIFT-JIS"
df_workers = pd.read_csv("correspondence.csv", encoding=enco)
# クロス集計表の作成
df_cross = pd.crosstab(df_workers["回答者"], df_workers["副業"])
# コレスポンデンス分析の実行
mca_counts = mca.MCA(df_cross, benzecri=False)
rows = mca_counts.fs_r(N=2)
cols = mca_counts.fs_c(N=2)
# 散布図の作図設定
plt.scatter(rows[:, 0], rows[:, 1], c='b', marker='o')
labels = df_cross.index
for label, x, y in zip(labels, rows[:, 0], rows[:, 1]):
plt.annotate(label, xy=(x, y))
plt.scatter(cols[:, 0], cols[:, 1], c='r', marker='x')
labels = df_cross.columns
for label, x, y in zip(labels, cols[:, 0], cols[:, 1]):
plt.annotate(label, xy=(x, y))
# 散布図の描画
plt.show()それぞれの記述内容について解説します.
① ライブラリのインポート
コレスポンデンス分析で用いるライブラリをインポートします.
5つのライブラリをインポートします.
# ライブラリのインポート
import mca
import matplotlib.pyplot as plt
import japanize_matplotlib
import pandas as pd
import chardet② データの読み込み
pd.read_csv関数を用いてCSVファイルの読み込み,データフレームに格納します.
データフレーム名(=の左側)は任意の値を入力します.””内は読み込むCSVファイル名を記述します.
2行目から10行目までは文字コード対応になります.read_csv関数実行時に文字コード関連のエラーが出た際は,参考にしてみてください.(基本的には最終行だけで読み込めます)
# CSVファイルの読み込み
with open("correspondence.csv", 'rb') as f:
binary = f.read()
d = chardet.detect(binary)
if d["encoding"] == "utf-8":
enco = "utf-8"
elif d["encoding"] == "UTF-8-SIG":
enco = "utf_8_sig"
else:
enco = "SHIFT-JIS"
df_workers = pd.read_csv("correspondence.csv", encoding=enco)③ クロス集計表の作成
読み込んだCSVファイルからクロス集計表を作成します.
データフレームからクロス集計表は,pd.crosstab関数を用いて作成することができます.1つ目の引数に表側とする列名(回答者),2つ目の引数に表頭とする列名(副業)を指定します.
# クロス集計表の作成
df_cross = pd.crosstab(df_workers["回答者"], df_workers["副業"])④ コレスポンデンス分析の実行
mcaライブラリのMCA関数を用いてコレスポンデンス分析を行います.
2行目のMCA関数の1つ目の引数に,クロス集計表のデータフレーム名を指定します.他の行はそのままの記述で大丈夫です.
# コレスポンデンス分析の実行
mca_counts = mca.MCA(df_cross, benzecri=False)
rows = mca_counts.fs_r(N=2)
cols = mca_counts.fs_c(N=2)⑤ 散布図の作図設定
散布図の作成はmatplotライブラリのpyplotモジュールを用いて行います.
散布図に使用するマーカーの色や記号は,2行目と7行目の引数で設定可能です.
# 散布図の作図設定
plt.scatter(rows[:, 0], rows[:, 1], c='b', marker='o')
labels = df_cross.index
for label, x, y in zip(labels, rows[:, 0], rows[:, 1]):
plt.annotate(label, xy=(x, y))
plt.scatter(cols[:, 0], cols[:, 1], c='r', marker='x')
labels = df_cross.columns
for label, x, y in zip(labels, cols[:, 0], cols[:, 1]):
plt.annotate(label, xy=(x, y))⑥ 散布図の描画
show関数で設定した散布図を描画します.
# 散布図の描画
plt.show()PyCharmを用いている方は右上の「▶」ボタンを押すとプログラムが実行されます.
結果の解釈
コレスポンデンス分析の結果の解釈について例題の結果から解説します.
プログラムを実行すると以下のような散布図が出力されます.
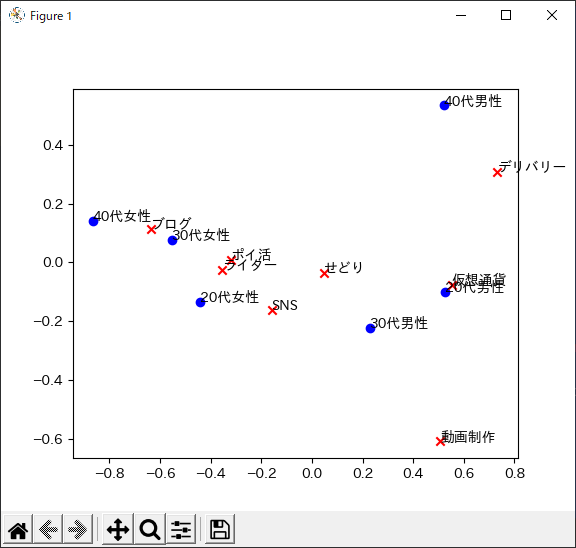
コレスポンデンス分析ではプロットされた位置が近いほど,項目間の関連性が強いことを意味します.
特に関連性が強いと判断できるのは,仮想通貨と20代男性です.プロット位置が非常に近いことから20代男性は副業として仮想通貨をよく行っているということがわかります.
同様にブログについては30代・40代女性がよく行っているということがわかります.
補足① コレスポンデンス分析とは
コレスポンデンス分析とは,多変量解析という統計解析手法の1つになります.多変量解析とは,多数の項目(説明変数)を持つデータを分析する際行う解析手法です.
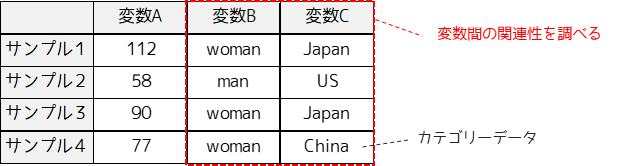
コレスポンデンス分析は多変量解析の中でも,カテゴリーデータの関連性を調べるため行います.(数量データに対しては主成分分析を行います)
クロス集計表から主成分分析と同じ方法でデータを縮約して,散布図にすることで視覚的に項目間の関連性を判断することができます.
補足② クラスター分析との違い
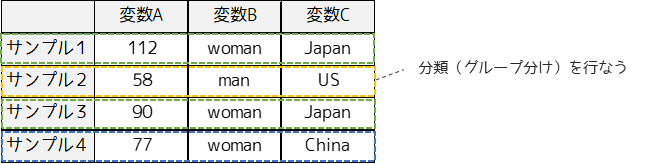
コレスポンデンス分析は出力結果が散布図であるため,非階層クラスター分析と類似した手法と思われがちです.しかし,コレスポンデンス分析とクラスター分析では分析の目的が大きく異なります.
コレスポンデンス分析は2つの変数(項目)の関連性を調べるために行います.
クラスター分析はサンプル間または変数間の分類を行なう手法です.例題では回答者ごとに分類を行いたい場合はクラスター分析を行います.
補足③ 統計解析アプリ
本サイトではより手軽にコレスポンデンス分析を実行して,クロス集計表の分析を行うアプリ(StaatApp)を販売しています.
詳細は以下のページで紹介しています.
》クロス集計表分析アプリ
》統計解析アプリStaatAppとは

補足④ PyCharmを用いた実行環境の構築
Pythonを初めて使う方や,自分のPCにPython・PyCharmが入っていない方は以下のページで解説している手順で実行環境の構築を行ってください.
初めて触る方にもわかりやすいようにPyCharmを用いた手順となっています.
コレスポンデンス分析では,”mca”というライブラリを使用します.インストール方法が分からない方は,ライブラリのインストールを参考にしてください.
》実行環境の構築方法【Pycharm使用】
》ライブラリのインストール方法【Pycharm使用】
補足⑤ Pythonで読み込むデータの作成方法
Pythonで扱うCSVファイルの作成方法は以下のページで解説しています.





