ノンパラメトリック検定である,マンホイットニーのU検定(ウィルコクソンの順位和検定)の大標本の場合について解説します.
マンホイットニーのU検定とは
マンホイットニーのU検定とは,対応のない2群の差の検定(対応のないt検定)のノンパラメトリック版です.順序尺度以上のデータに対して用いることができます.
ウィルコクソンの順位和検定と呼ばれることもありますが,手法自体は同じです.
マンホイットニーのU検定の考え方は以下になります.
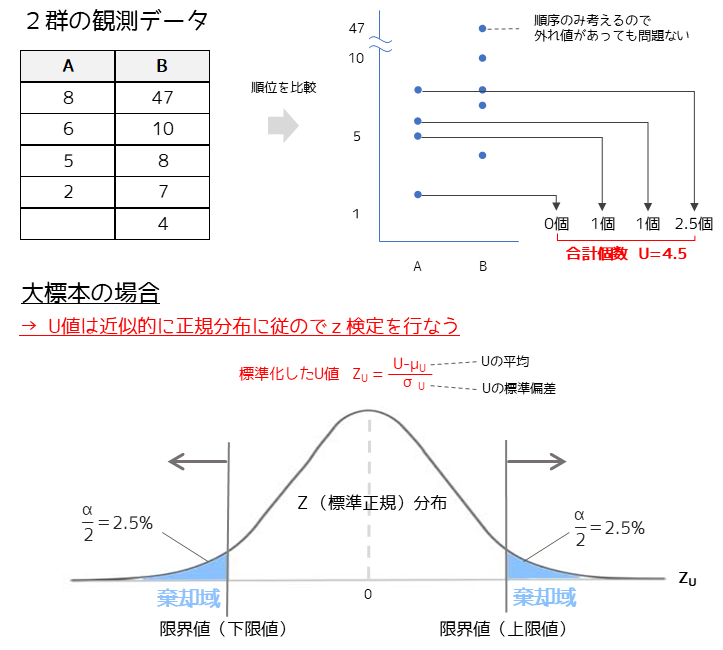
マンホイットニーのU検定では,2群のデータを順番に並べて順位を比較します.片方の群の値以下の,もう片方の値の個数を合計した値がU値になります.
大標本の場合はU値が近似的に正規分布に従うので,U値を標準化してz検定を行います.大標本とは片方のサンプルサイズが21以上,もしくは両群が8以上の場合です.
標準化したU値からp値を求め,有意水準より小さい場合は2群に差があると判定します.
マンホイットニーのU検定の手順
マンホイットニーのU検定は以下の手順で行います.
① 仮説の設定
帰無仮説は「2群の母集団に差がない」,対立仮説は「2群の母集団に差がある」として設定します.
② 有意水準の決定
マンホイットニーのU検定では有意水準α=0.05,もしく0.01とします.
③ 標準化したU値とp値の算出
具体的な計算手順は,Excelを用いた方法で解説しています.
④ 有意差判定
・p値<有意水準であれば,帰無仮説は棄却されて対立仮説を採択 → 「2群の母集団に差がある」
・p値\(\geq\)有意水準であれば,帰無仮説は棄却されない → 「2群の母集団に差があるとは言えない」
仮説検定の考え方や用語については,以下のページで解説しています.
検定結果を間違いたくない方へ
Excelを用いた計算方法より簡単・正確に,マンホイットニーのU検定の検定結果を調べることができる,統計解析アプリStaatAppを配布しております.StaatAppでは標本数によって最適な計算方法で,マンホイットニーのU検定が実行されます.
初めての方はほぼ全ての機能を無料で利用できるので,お気軽にダウンロードしてお使いください!
》StaatAppで行う仮説検定
》統計解析アプリStaatApp

例題で用いるデータと仮説の設定
例題では以下のサンプルデータを用います.AクラスとBクラスのテストの点数になります.
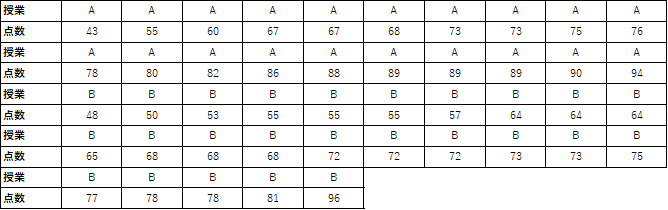
帰無仮説は「2つのクラスの点数に差がない」となり,対立仮説は「2つのクラスの点数に差がある」と設定します.
有意水準α=0.05で両側検定を行います.
Excelを用いた計算手順
Excelを用いた検定統計量の計算手順について説明します.
以下のような表を作成して,標準化したU値とp値を求めます.
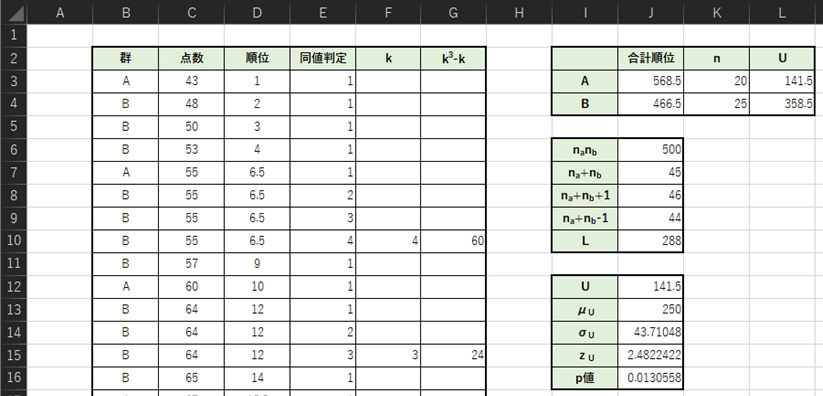
各セルの数式一覧は以下のようになります.
・D列:=RANK.AVG(C3,C:C,1) ※3行目のセルの数式です.下の行へは数式のコピーを行ってください.
・E列:=IF(C2=C3,E2+1,1)
・F列:=IF(AND(OR(E4=1,E4=””),NOT(E3=1)),E3,””)
・G列:=IF(F3=””,””,F3^3-F3)
・J3:=SUMIFS(D:D,B:B,I3)
・K3:=COUNTIFS(B:B,I3)
・L3:=J6+(K3*(K3+1))/2-J3
・J6-9:項目名通りの計算式(nはサンプル数)
・J10:=SUM(G:G)
・J12:=MIN(L3:L4)
・J13:=J6/2
・J14:=SQRT((J6*J8)/12-(J6/(12*J7*J9))*J10)
・J15:=ABS((J12-J13))/J14
・J16:=2*(1-NORMSDIST(J15))
入力式と計算手順について解説します.
① データを入力して昇順に並び替える【B列】【C列】
群(クラス)と値(点数)を各1列にデータを入力します.
入力データを並び替え機能を用いて,昇順に並び替えます.
② 順位を求める【D列】
並び替えた値を順位データに変換します.
順位データはRANK.AVG関数を用いて計算します.RANK.AVG関数の引数は以下になります.
RANK.AVG(“順位に変換する値”,”順位の対象となるデータ群(列)”,1)
※ 例題では値が小さいほど順位が高くなるように計算します.
③ 補正項を求める(タイデータがある場合)【E列】【F列】【G列】【J10】
順位データに同じ値(タイデータ)がある場合,U値の標準偏差を求める際に必要な補正項を求めます.補正項は以下の式で求めることができます.
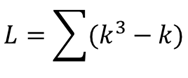
kはタイデータの個数になります.例題では,6.5位が4つあるためk=4となります.全てのタイデータに対してk3–kを求め,その総和が補正指数Lになります.
補正項を「J10」セルで計算するために,「E列」・「F列」・「G列」で必要な値を計算します.
④ 各群の合計順位を求める【J3】【J4】
U値の計算に必要な各群の合計値(順位和)を計算します.
特定の列の値ごとに合計値を計算するためにSUMIFS関数を用います.SUMIFS関数の引数は以下になります.
SUMIFS(“合計する値の範囲(列)”,”合計するか判定する値の範囲(列)”,”判定する値の範囲と一致させる値”)
⑤ サンプルサイズを求める【K3】【K4】
各群のサンプルサイズ(データ数)を求めます.COUNTIFS関数を用いて,「B列」に”A”と”B”がいくつあるかカウントします.
⑥ 事前に必要な値を計算する【J6-9】
Excelでは,長い数式を1つのセルで行うと可読性が低くミスを起こしやすいので,U値の算出や標準化する際に,必要ないくつかの項の計算を各セルで予め行います.
naとnbは⑤で求めた各群のサンプルサイズを示しています.
⑦ 各群のU値を求める【L3】【L4】【J12】
各群のU値を求めます.U値は以下の式で求めることができます.
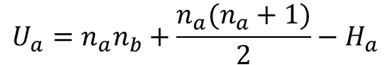
Haは④で求めたAクラスの順位和です.
Bクラスについても同様にU値を求めて,UaとUbのうち小さい値を検定に用いるU値として「J12」セルに入力します.
⑧ U値の平均μUを求める【J13】
U値の平均μUは以下の式で求めることができます.
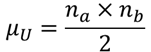
⑨ U値の標準偏差σUを求める【J14】
U値の標準偏差σUは以下の式で求めることができます.

タイデータがない場合は補正項を除いて計算することができます.
⑩ 検定統計量zを求める【J15】
U値を標準化した検定統計量zUは以下の式で求めることができます.
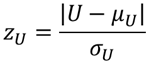
⑪ p値を求める【J16】
検定統計量zUからNORMSDIST関数を用いてp値を求めます.
例題では計算結果から,p値が0.013..でp値<有意水準となり帰無仮説は棄却され対立仮説が採択されます.結論としては,「AクラスとBクラスのテストの点数は差がある」となります.
補足① Excelを用いた片側検定の計算方法
「Bクラスのテストの点数はAクラスより低い」という仮説を検証したいとします.
帰無仮説は「AクラスとBクラスのテストの点数は同じ」となり,対立仮説は「Bクラスのテストの点数はAクラスより低い(母集団の点数分布の中央値がBクラスの方が小さい)」となります.
対立仮説を比較するデータの大小について設定した場合,片側検定を行う必要があります.
U値を標準化したzUを求める手順は,既に説明した計算手順と同じです.⑪で最後に求めたp値が異なります.Excelの片側検定では以下の式を用いてp値を計算します.
片側検定のp値=1-NORMSDIST(”検定統計量”)
「J18」セルに入力する式としては以下のようになります.
ex) 「J18」セルの入力式:=1-NORMSDIST(J17)
この結果,p値は0.0065..となり有意水準α=0.05より小さいことが分かります.よって帰無仮説は棄却され対立仮説を採択します.結論としては「Bクラスのテストの点数はAクラスより低い」となります.
補足② 効果量の求め方(Excel版)
仮説検定の結果として重要な効果量の求め方について,Excelを用いて解説します.
ノンパラメトリック検定の効果量rは,以下の式で求めることができます.
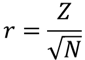
効果量と検定力分析入門 水本・竹内(2010)
※ 効果量には様々な計算方法があるため,論文などでは引用元もしくは計算式を示す必要があります.
例題では標準化した検定統計量Z=2.482..でサンプルサイズN=45となり,効果量r=0.370..となります.
効果量rの値の目安としては次のようになるので,比較した2群には統計学的に少し大きい差があると判断することができます.
【効果量rの目安】 小:0.1 中:0.3 大:0.5
補足③ サンプルサイズが小さい場合
大標本の場合のマンホイットニーのU検定では,正規化近似(Excelの計算手順⑧-⑪)を行いz検定を行いました.用いるデータのサンプルサイズが小さい場合は,U値の正規化近似を行うことができないので,専用の検定表を用いたU検定を行う必要があります.
サンプルサイズが小さい基準目安としては,両群のサンプルサイズがともに20以下,もしくは片方が7以下の場合であることです.
例えば,Aクラスの点数を聞いた大学生が19人でBクラスの点数を聞いた大学生が16人だった場合は,専用の検定表を用いたU検定を行ってください.
小標本に対するマンホイットニーのU検定の考え方や手順は,下記ページで解説しています.
補足④ データの前提条件
補足③に加えて,用いるデータの前提条件を解説します.
① ノンパラメトリックなデータ
マンホイットニーのU検定はノンパラメトリックな(=正規分布でない)データに対して行います.用いるデータが正規分布と仮定できる場合は,マンホイットニーのU検定を行うことも可能ですが,多くの場合でt検定を行います.(検出力がt検定に比べて95%であるため,t検定を用いることが多いです.)
② 順序尺度
名義尺度のデータに対しては用いることができません.名義尺度はデータの大小に意味が無い,つまり順位和を求めることができないことから明らかです.名義尺度のデータの差や関連性を分析する際は,クロス集計表を用います.
③ 対応のないデータ
比較する2つのグループは対応のない場合である(異なる個体のデータ)である必要があります.対応のある場合は,ウィルコクソンの符号順位検定を行います.
④ 等分散性があるデータ
比較する2つのデータの分布(特に分散)が異なる場合,マンホイットニーのU検定は正確に検定することができません.分布が等しくない場合,ブルンナー・ムンチェル検定を行います.