



因果推論の代表的な手法である傾向スコアマッチングについて,実践例を用いて解説します.
実践例で使用している統計解析アプリStaatAppはこちらのページから無料でダウンロードできます.(傾向スコアマッチングは有料機能となります.)
傾向スコアマッチングとは
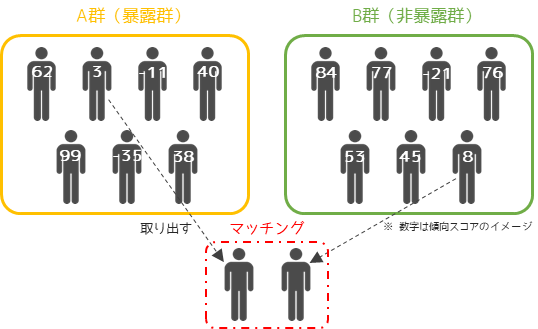
統計学において異なるサンプルで,似ている要素(交絡因子)をもつデータを見つけてペアにすることをマッチングと言います.
傾向スコアマッチングとは,マッチングの際のペアを見つける基準として傾向スコアを用いる手法になります.
一般的には傾向スコアは,目的変数を原因の変数(A群=1,B群=0)に説明変数を交絡因子にしてロジスティック回帰や決定木分析を行うことで求めます.
傾向スコアマッチングの手順
傾向スコアマッチングは以下の手順で行います.
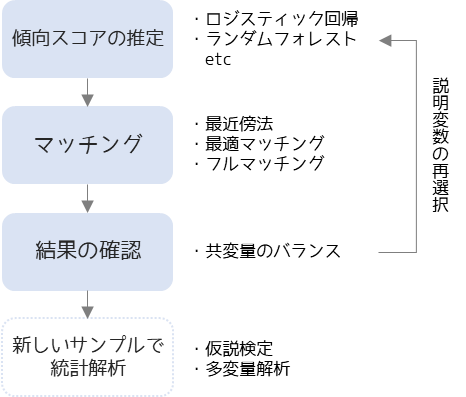
最初にロジスティック回帰分析などを行い,傾向スコアを計算します.
求めた傾向スコアからマッチングを行います.マッチング方法には強欲マッチングや最適マッチングといった方法があります.
マッチングを行い新しいサンプルを抽出したら,2群(暴露群・処置群と非暴露群・対照群)に分けて共変量のバランスを確認します.バランスが取れていない場合は,交互作用項や2乗項を説明変数に加えて再度傾向スコアを計算します.
共変量のバランスが取れている場合は,マッチング済みの新しいサンプルを用いて仮説検定や多変量解析のような統計解析を行います.
StaatAppを用いた傾向スコアマッチング
統計解析アプリStaatAppを用いて,実際に傾向スコアマッチングを用いて因果推論を行います.データサイエンス・機械学習の競技プラットフォームであるKaggleで使用されるタイタニック号のデータセットを用いて解説します.
データ分析の目的は「”生存状況”によって”年齢”に差があるか」とします.この際に処置変数は”生存状況”となり,共変量(交絡因子)を”兄弟/配偶者数”・”親/子ども数”・”旅客運賃”として傾向スコアマッチングを行い,交絡因子の影響を取り除いた上で仮説検定を行います.
解説で用いるデータは以下になります.
① 傾向スコアの算出
傾向スコアの算出を行います.今回はロジスティック回帰分析を用いて傾向スコアを算出します.ロジスティック回帰分析の詳しい方法については以下をお読みください.
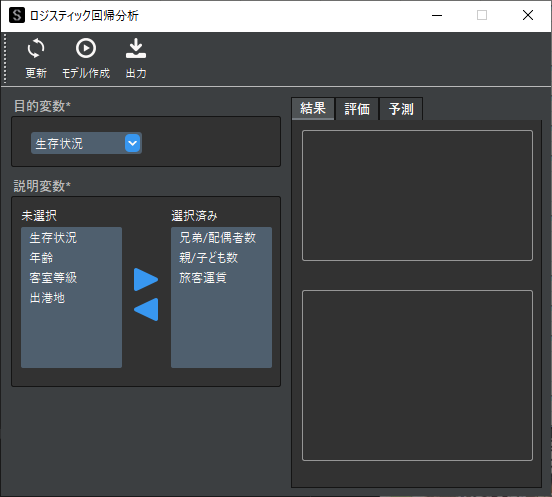
目的変数には処置変数(生存状況)を設定し,説明変数には共変量を設定してロジスティック回帰分析を実行します.
モデル作成を行ったら「予測」タブを選択して,「算出」ボタンをクリックし予測確率を算出します.
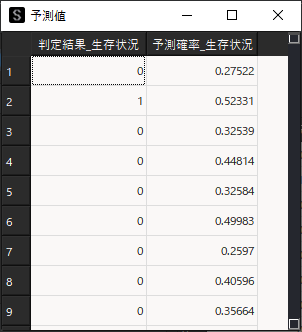
算出した予測結果をツールバーの「出力」機能で「データ2」に出力して,データ操作画面のツールバー「結合」機能を用いてサンプルデータと予測結果のデータを結合します.
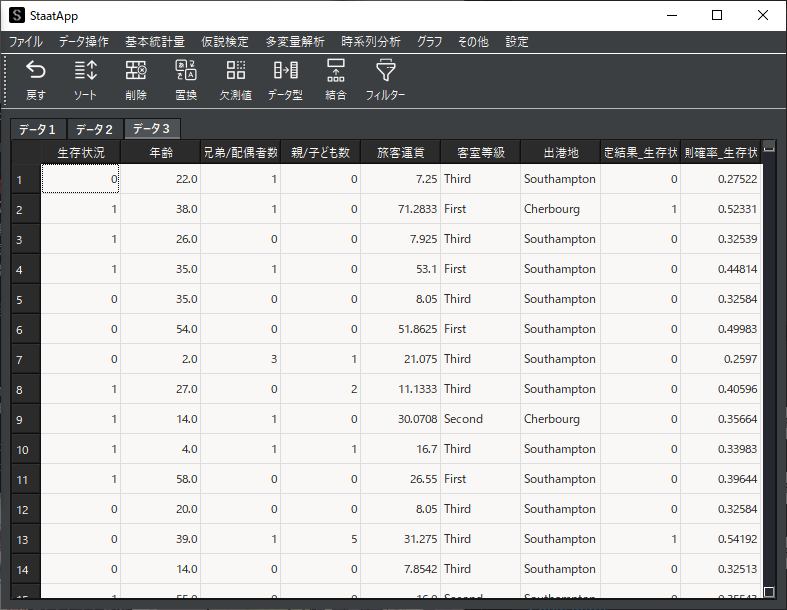
② 傾向スコアマッチングの実行
①の手順で作成した以下のデータを対象に,傾向スコアマッチングを行います.
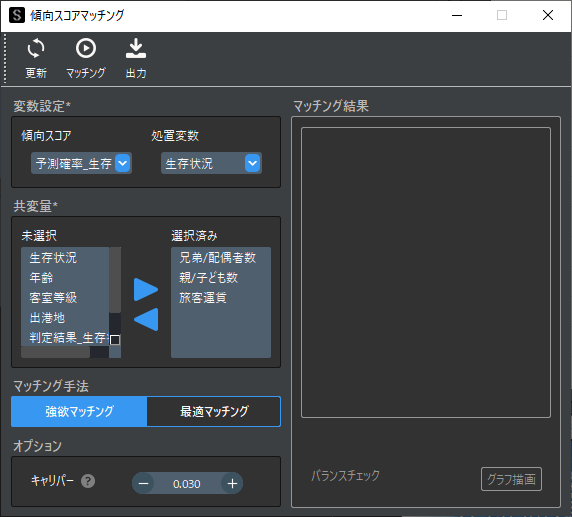
メニューバーから「その他」→「傾向スコアマッチング」を選択して,傾向スコアマッチング用ウィンドウを表示します.
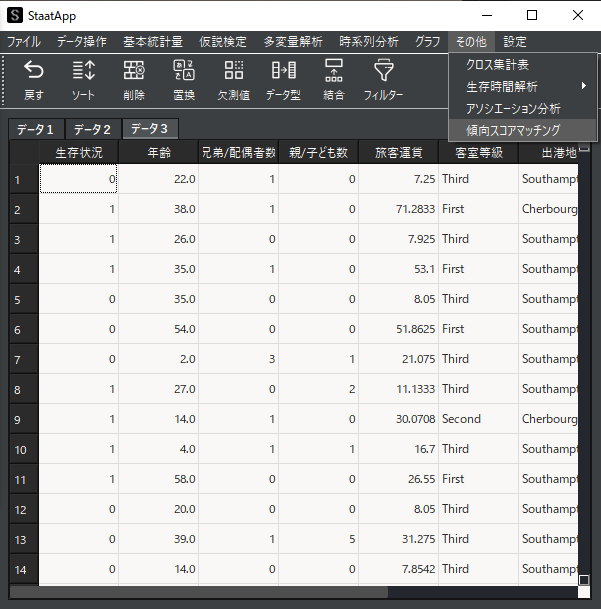
傾向スコアにはロジスティック回帰分析で算出した予測確率を選択して,強欲マッチングを行います.
※ キャリパー(許容範囲)は傾向スコアの標準偏差✕0.2で自動設定されます.
③ マッチング結果とバランスチェック
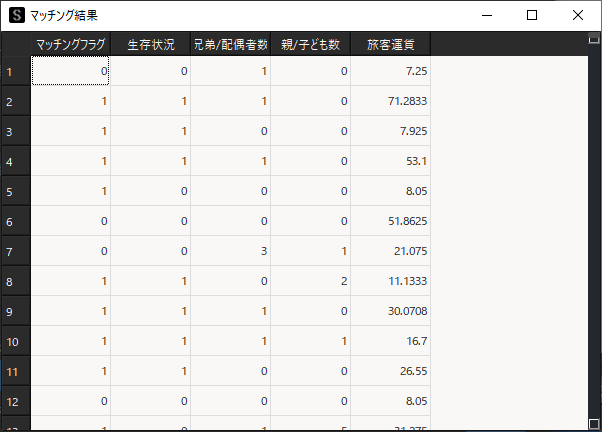
マッチング結果は”マッチングフラグ”として算出されます.”マッチングフラグ”が”1″のレコードがマッチングしたデータになります.
「グラフ描画」ボタンを選択して,マッチング結果のバランスチェックを行います.共変量ごとにバイオリンプロットが作成されます.
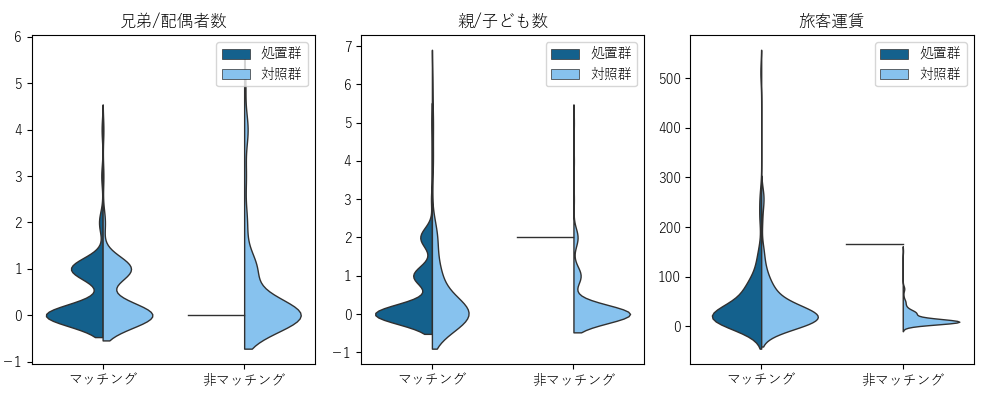
バイオリンプロットからマッチング済みのデータの方が,処置群と対照群でバランスよくデータが分布していることがわかります.
④ マッチング済みデータの抽出
マッチング結果を「データ1」に出力して,マッチング済みデータのみを取り出します.マッチング結果にはアウトカム変数(検定対象)である”年齢”データが含まれていないので,抽出前にマッチング結果と”年齢”を含むデータの結合が必要です.
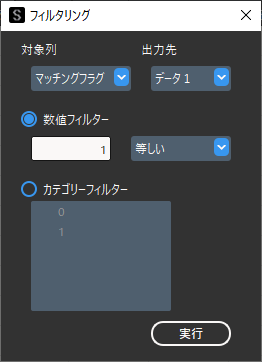
結合が完了したら”マッチングフラグ”と処置変数,アウトカム変数を含む「データ1」を対処にフィルター機能で,”マッチングフラグ”が”1″のレコードのみを抽出します.
⑤ 対応のないt検定の実行
マッチング済みデータを用いて,データ分析の目的であった「”生存状況”によって”年齢”に差があるか」という仮説を対応のないt検定を用いて判定を行います.
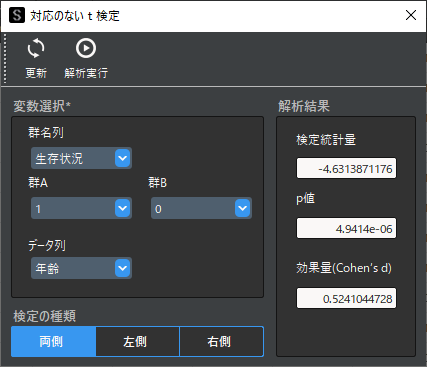
p値<0.05となったので,「”生存状況”によって”年齢”に差がある」という結論が得られます.
ここまでがStaatAppを用いた傾向スコアマッチングの例になります.StaatAppではロジスティック回帰分析以外にも多様な手法で傾向スコアの算出することができます.
マッチング済みデータの解析手法についても,対応のないt検定以外にも多様な手法が実行可能です.

補足① マッチング方法
StaatAppではマッチング方法として,強欲マッチングに加えて最適マッチングが実行可能です.最適マッチングはデータ全体に対して演算を行いため,データサイズが大きいほど計算時間が必要となります.
補足② マッチングのアルゴリズム
マッチングでは,以下のライブラリ・アルゴリズムを用いています.
・強欲マッチング(sklearn)
・最適マッチング(networkx)




