データクレンジングについての重要性や流れ,具体的な方法について解説します.
データクレンジングとは
データクレンジングとはデータ分析を行いやすくする,正しい分析結果を得るためにデータをきれいにする(クレンジング)ことです.
既存データに対してデータクレンジングを行わないまま分析を行った場合,誤った分析結果になる可能性があります.
例えば以下のように,入力規則・表記方法がばらばらのデータがあるとします.データクレンジングを行わないまま分析を行った場合,3人の被験者は同じ回答内容であるはずなのに異なる結果として分析される,もしくは計算自体が上手くできないといった問題が発生します.
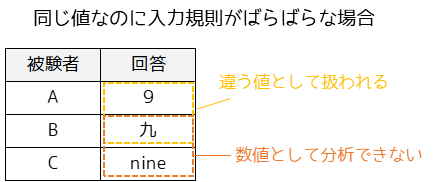
データクレンジングでは具体的に,データの削除や置換といった作業を行います.先程のデータ(ダーティデータ)を置換することで,正しい分析が可能なデータを得ることができます.

データ分析に影響を及ぼす値
実際にデータクレンジングを行う対象となる値,ダーティデータの要素は以下のようになります.
・外れ値
・欠測値
・単位の違うデータ
・表記ゆれのあるデータ
・重複のあるデータ
以上のような値がデータに含まれる場合は,分析前にデータクレンジングを行う必要があります.
データクレンジングの流れ
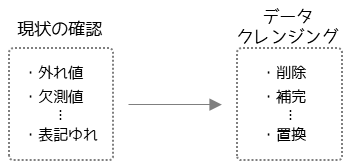
データクレンジングを行う前に扱うデータの現状を確認する必要があります.取り扱うデータに対して,データ分析に影響のある値の有無を確認します.
データ分析に影響のある値が混入している場合,それぞれの場合に合わせた方法でデータクレンジングを行います.例えば,外れ値が含まれる場合はその値の削除を検討します.
データの現状確認
主なデータの確認方法・観点は以下になります.
① 数値データ(半角・全角)の確認
どのような分析ツールを用いる場合でも,数値データを数値として扱うためには入力された値が”半角文字”である必要があります.全角文字である場合は数値として扱われません.数値として分析を行いたい変数(列)に全角文字が含まれていないか確認する必要があります.
確認方法としては,各ソフトやプログラミング言語に実装されているデータ型判定機能を用います.
② 数値データ(分布)の確認
数値データに対して外れ値があるかを調べるためには,分布の確認を行います.
分布は主にヒストグラムや散布図を用いて調べることができます.グラフを用いて数値データを可視化することで外れ値を発見することができます.
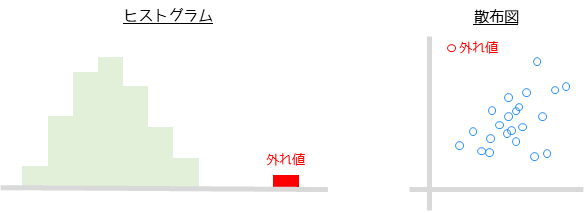
数値データにありがちな単位違いについても,可視化することで外れ値として発見することができます.
③ カテゴリーデータの確認
数値データ以外のデータであるカテゴリーデータでは,表記ゆれがないか確認する必要があります.
表記ゆれの確認方法としては,一意のリストを作成する方法が有効です.
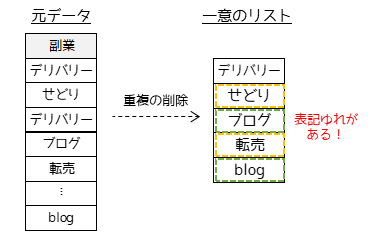
重複を削除した一意のリストを作成することで,同じカテゴリーとして扱いたいデータの重複を発見することができます.Excelの場合は「フィルター」機能を用いることで簡単に確認することができます.
④ 重複データの確認
数値データ・カテゴリーデータに依らず,全く同じ値を持つデータ(行)を重複データと言います.
重複データの確認は各ソフトに実装されている機能の利用や,プログラミング言語であれば関数を利用することで行うことができます.Excelの場合は「条件付き書式」機能を利用することで重複セルに色付けすることができます.
⑤ 欠測値の確認
欠測値とは回答者の未回答や入力漏れなどの理由で,値が記録されていないデータになります.
欠測値は各ソフトやプログラミング言語によって表示方法が異なります.Excelであれば”空白のセル”となり,Pythonであれば”NaN”と表現されます.
欠測値の確認は検索機能を利用して,表示される形式に合わせた文字列の検索を行うことで可能です.
表記ゆれの対処方法
表記ゆれは全て”置換”を行うことで対処することができます.
置換は置換前のデータと置換後のデータを1種類ずつ指定して変換する必要があります.この作業はデータクレンジングの中でも非常に大変な作業で,基本的には誤った表記のデータを1つ1つ確認して変換していく必要があり大規模データの場合は膨大な時間が必要となります.
外れ値の対処方法
外れ値への対応は慎重に行う必要があります.外れ値とは集団から離れたデータであるため,基本的には取り除いた方が集団の特徴が得られやすく正しい分析を行うことが可能です.
しかし,外れ値が本当に取り除いてよいかはその値自体を確認して吟味する必要があります.外れ値である原因が明らかに入力ミス・測定ミスだと考えられるデータ(異常値)は取り除いても問題ありません.逆にこのように原因が明らかでない場合は外れ値を取り除いてはいけません.年収を調査した際にとんでもない金額の人がいたとしても,明らかに間違いでない場合以外は取り除いて分析を行ってはいけません.
単位や桁の違いで外れ値が生じている場合は,基準となる単位・桁数に変換を行います.
重複データの対処方法
重複データに対しては該当するデータ(行)が1つになるように削除を行います.
表記ゆれ対処のために既に置換を行ったデータである場合は,元データから本当に全く同じデータなのかを確認してから削除しましょう.
欠測値の対処方法
欠測値は削除または補完することで対処します.欠測値の対応方法は常にデータ分析者を悩ませる問題でもあり,一概にこのやり方で処理すればよいといった方法はありません.
① 削除する方法
欠測値に対して削除する方法として,ペアワイズ除去とリストワイズ除去があります.
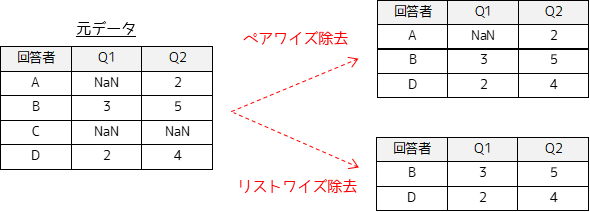
ペアワイズ除去では全ての変数が欠測であるデータ(行)のみを削除します.リストワイズ除去では欠測値が含まれるデータ全てを除去します.
削除する対処方法に共通するデメリットとして,サンプルサイズが小さくなるため標準誤差が大きくなります.大量のデータに対して欠測値が少ない場合は有効な手段ですが,サンプルサイズが小さい場合は削除すると分析自体が不可能になる場合もあるため補完する方法を検討する必要があります.
欠測値の発生がランダムでない場合(回答者が答えづらい質問に対して未回答とする場合など)も,データ削除することでバイアスが発生する可能性があるため補完する方法を検討します.
② 補完する方法
補完とは欠測値に対して適当な値を当てはめる処理になります.補完方法には単一代入法と多重代入法があります.
単一代入法では全ての欠測値に対して同じ変数の平均値や中央値を代入します.単純な方法のため比較的簡単に実行することができますが,本来のデータとは異なる結果が生じる可能性があります.
多重代入法では欠測値を代入したデータセットを複数作成して,それぞれのデータセットに対して分析を行い最終的にそれらの結果を統合します.機械学習の分野でよく用いられる方法ですが,実際の実行するのは難しいです.(自らプログラムを作成する必要があります.)
補足① Pythonを用いたデータクレンジング
データクレンジングについてより具体的に紹介するために,Pythonを用いた方法を以下のページで解説しています.
補足② StaatAppを用いたデータクレンジング
統計解析アプリStaatAppではデータ操作機能が実装されており,クリック操作だけで手軽にデータクレンジングを行うことができます.
初めての方はほぼ全ての機能を無料で利用できるので,お気軽にダウンロードしてお使いください!
》統計解析アプリStaatApp
》StaatAppで行うデータクレンジング

補足③ きれいなデータセットの重要性
データクレンジングは既存のデータを分析するための前処理になります.データクレンジングはデータ分析の中でもコストが大きい作業であり,欠測値の処理ではバイアスを生じる可能性が大いにあります.
このことからもデータ分析においては,データクレンジングの正確性よりもそもそもデータクレンジングを行わなくてよい”きれいな”データセットの作成・入力が重要になります.(既存のデータに対してはどうしようもないですが,,)
きれいなデータセットを作成するためには,本ページで紹介したデータ分析に影響を及ぼす値が発生しないように意識・規定づくりをする必要があります.自分がデータセットを作成する立場にある場合は,データクレンジングが必要のないデータ作成をしましょう.