



StaatAppでクラスター分析を行う方法を紹介します.CSVファイルやExcelファイルを読み込み,マウス操作だけでクラスター分析を行うことができます.
StaatAppでは非階層クラスター分析で代表的なK-means法と,階層クラスター分析を行うことが可能です.
アプリの基本操作
StaatApp基本操作(データの入出力など)は以下のページで解説しています.
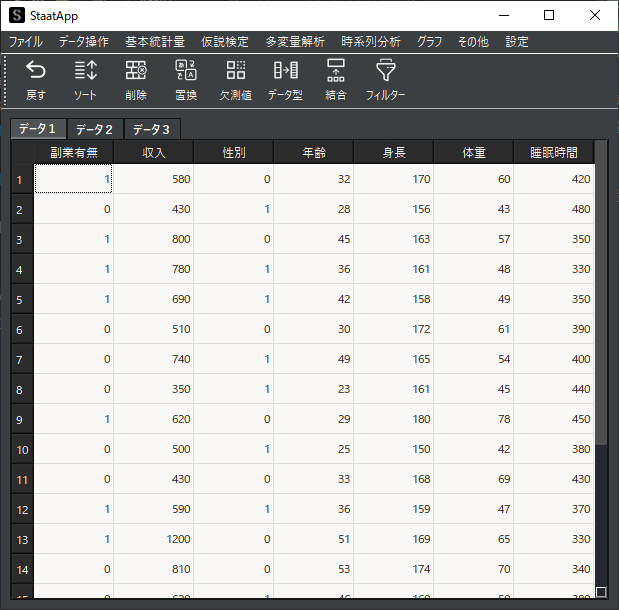
分析例として用いるサンプルデータは以下のようになります.”副業有無”と”性別”はダミー変数となっていますが,置換機能を用いてダミー変数に変換することも可能です.(副業有→”1″,女性→1″)
k-means法の実行方法
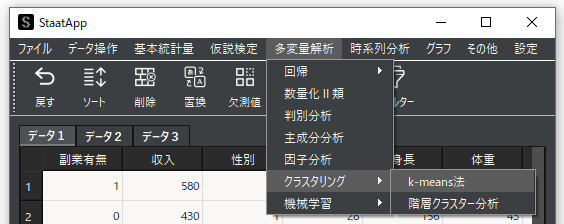
① k-means法の選択
メニューバーから「多変量解析」→「クラスタリング」→「k-means法」を選択します.
② 変数の選択
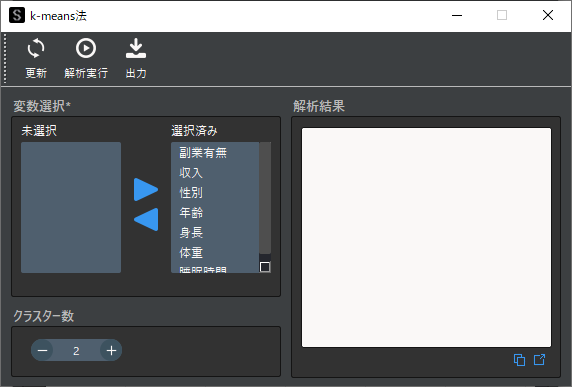
k-means法用のウィンドウが表示されたら,クラスタリング対象を選択します.
ダミー変数を選択する際は,多重共線性の問題を回避するために1列分を除いて選択します.サンプルデータは既に1列分除いたダミー変数になっています.
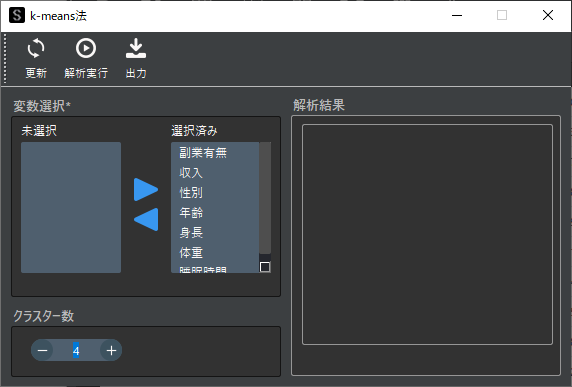
③ クラスター数の設定
クラスタリングを行う集団の数(クラスター数)を設定します.以下の画像ではクラスター数を4と設定しました.
④ 解析の実行
設定が完了したらツールバーの「解析実行」ボタンをクリックしてk-means法を実行します.実行結果は以下のように表示されます.
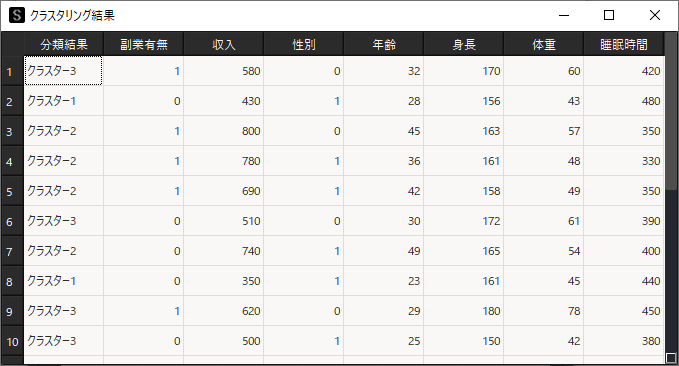
選択した変数データの先頭列”分類結果”という列が追加されます.この”分類結果”列にある値がクラスタリングした結果の属する集団を示す番号になります.
⑤ クラスタリング結果の分析(応用)
クラスタリング結果は,「分類結果」列のクラスター番号を用いて様々な分析が可能です.追加で分析を行なう場合は出力機能を用いて,データ操作画面に保存します.
基本統計量(平均値や中央値)を,各クラスターの特徴を把握したい場合は,基本統計量機能(無料)を用います.
基本統計量機能で以下のように,「カテゴリー分類」にクラスター番号が入った列を指定します.
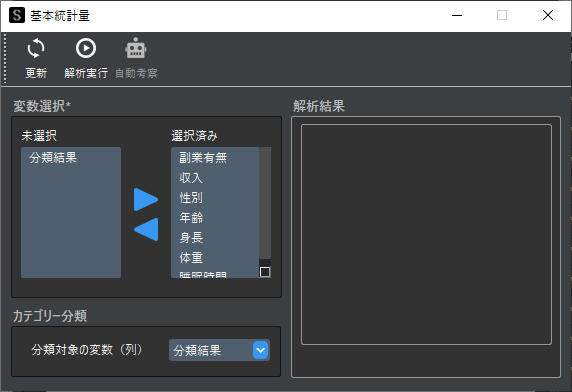
「解析実行」をクリックすると,変数・クラスターごとの統計量が表示されます.
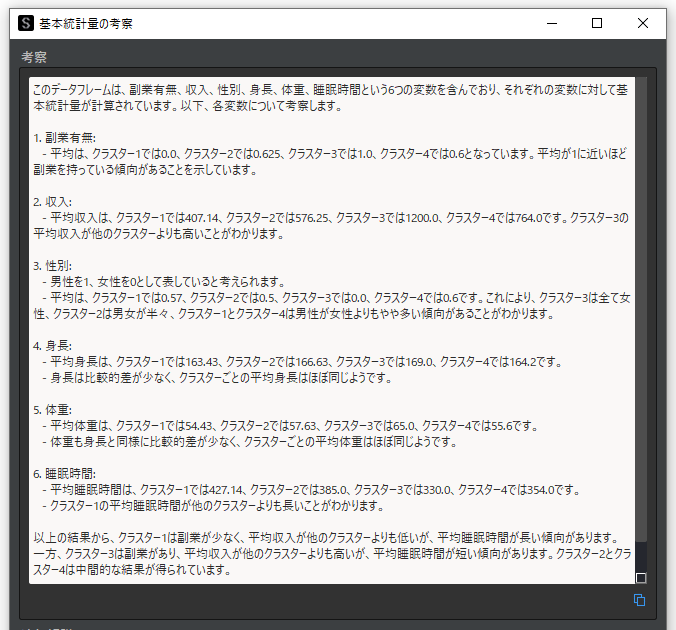
さらに自動考察機能を用いると,クラスターごとに以下のような考察を得ることができます.
⑤ クラスタリング結果の可視化(応用)
クラスタリング結果は散布図やバブルチャートなどで可視化することができます.クラスタリング結果を出力機能を用いて,データ操作画面に保存します.
保存したデータを対象に散布図・バブルチャート機能(無料)で以下のように設定をします.「分類選択(オプション)」で分類結果を選択するのが,ポイントです.
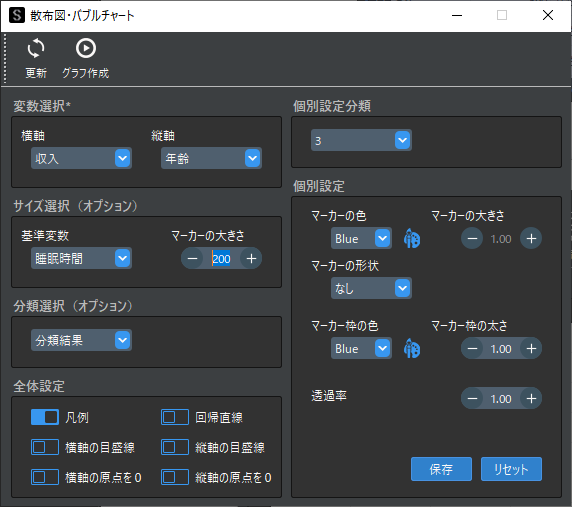
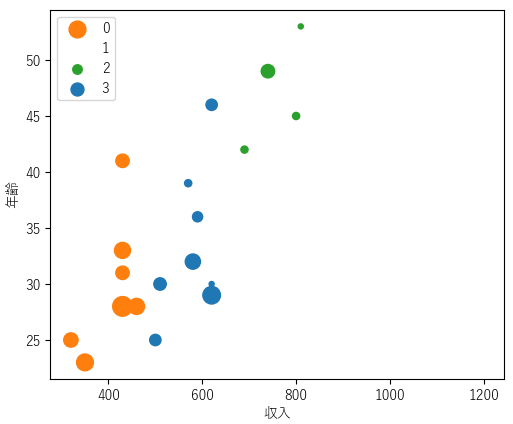
以下のようにクラスタリング結果ごとに色付けしたバブルチャートを作成することができます.
階層クラスター分析の実行方法
① 階層クラスター分析用ウィンドウの表示
メニューバーから「多変量解析」→「クラスタリング」→「階層クラスター分析」を選択します.
② 変数の設定
階層クラスター分析用のウィンドウが表示されたら,クラスタリング対象とする変数名を選択します.
③ 距離測定法・クラスタリング手法の設定(任意)
距離測定法とクラスタリング手法の設定が可能です.デフォルトでは階層クラスター分析で最も一般的な手法が設定されているため,特にこだわりがない場合は設定する必要はありません.
詳しくは補足④をお読みください.
④ 解析の実行
設定が完了したらツールバーの「解析実行」ボタンをクリックして階層クラスター分析を実行します.
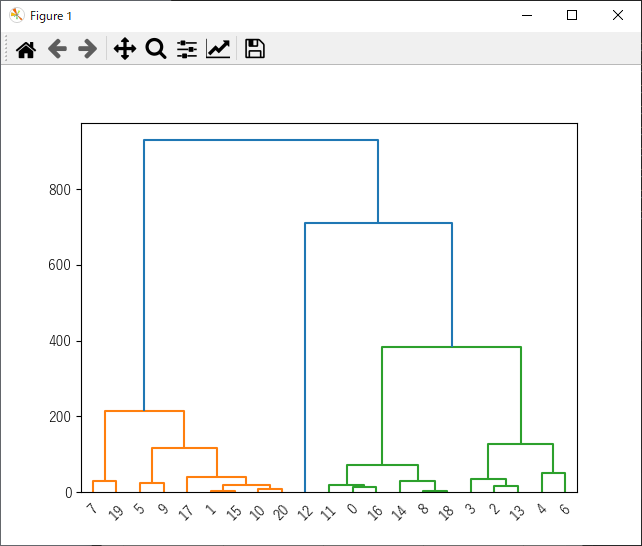
実行すると画像のようなデンドログラム(樹形図)が表示されます.樹形図の分岐が近いサンプルほど類似したクラスターに分類されていることがわかります.
表示されたグラフ上部のメニューを選択することで,目盛りや軸ラベルの設定,画像の保存を行うこともできます.
補足① 結果の見方
クラスター分析で出力された結果の見方は,以下のページでそれぞれ解説しています.
》K-means法(非階層クラスター分析)
》階層クラスター分析
補足② 統計アプリStaatAppとは
StaatAppは計算仮定が複雑な解析手法を,誰でも手軽に素早く行なうことができるアプリです.StaatAppの詳細は以下のページをお読みください.

補足③ 階層クラスター分析と非階層クラスター分析
非階層クラスター分析では,樹形図を作成しません.クラスター分析を行う前にグループ数を決めて行う必要があります.
一方で,階層クラスター分析は計算量が膨大になるためビッグデータを分析したい際には不向きです.階層クラスター分析を行うサンプル数の目安は100以下になります.
補足④ 距離測定法・クラスタリング手法
StaatAppでは距離測定法・クラスタリング手法を以下の方法で設定可能です.
| 距離測定法 | クラスタリング手法 |
| ユークリッド距離(既定値) | ウォード法 ※ユークリッド距離のみ有効 |
| 標準化ユークリッド距離 | 最短距離法(最近隣法) |
| マハラノビスの距離 | 最長距離法(最遠隣法) |
| マンハッタン距離(市街地距離) | 重心法(重心までの距離)※ユークリッド距離のみ有効 |
| チェビシェフ距離(最大座標差) | 群平均法 |
| ミンコフスキー距離 | メディアン法 ※ユークリッド距離のみ有効 |
補足⑤ アプリの仕様について
アプリではPythonのscikit-learnライブラリとScipyライブラリ用いてクラスター分析を行っています.scikit-learnとScipyはPythonで統計解析や機械学習を行なう際に使用される一般的なライブラリです.
以下の公式ドキュメントに詳細な仕様が記載されています.
➔ K-means法の公式ドキュメント
➔ 階層クラスター分析の公式ドキュメント




