多変量データを対象とした統計量の求め方を紹介します.
特定の列のデータの分類ごとに統計量を求める方法と,単純に特定の列のデータ自体の統計量を求める2つの方法を紹介します.
groupby関数の使い方
groupby関数は,同じ値を持つデータをまとめるために使う関数になります.
使い方の例を示すために,下記のデータセットを用意します.
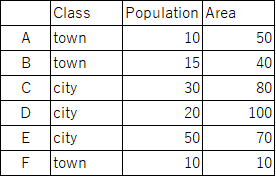
初めに,Class列の値でグループを作ります.
# ライブラリのインポート
import pandas as pd
import scipy as sp
# データの読み込み
city_info = pd.read_csv("city.csv")
# グループを作成する
group = city_info.groupby("Class")groupという変数に,townとcityごとにまとまったデータが代入されたのでこの変数に対して統計量を求めます.
# グループごとの平均を求める
print(group.mean())
# グループごとの標準偏差を求める
print(group.std(ddof = 1))統計量はScipyのライブラリを用いて求めます.出力結果は下記のようになります.
Population Area
Class
city 33.333333 83.333333
town 11.666667 33.333333
Population Area
Class
city 15.275252 15.275252
town 2.886751 20.816660このように,groupby関数を用いることである値でデータをまとめて,そのまとめたグループごとに操作を行うことが可能です.
列ごとの統計量の求め方
特定の列の統計量を求める方法を紹介します.
使うデータセットは先ほどと同様のものを使います.
# ライブラリのインポート
import pandas as pd
import scipy as sp
# データの読み込み
city_info = pd.read_csv("city.csv")
# 列ごとの平均を求める
print(city_info.Population.mean())データフレームに格納したデータに対して,ドット記号を用いて列を指定します.
加えて,統計量を求める関数を使うことで特定の列の統計量を求めることができます.
Sponsored Links
Sponsored Links