



対応のないt検定とは
対応のないt検定とは,別の個体(人や物)から得られたデータに差があるかを判定する統計学的手法になります.対応のあるt検定とは計算方法が異なるので注意してください.
t検定では2グループの標本平均を比較して,その差が母集団においてもあると言えるのかを確率的に判断します.
例えば,破壊試験や性別などの属性の比較を行なう場合に用いられます.
対応のないt検定の手順
対応のないt検定は,以下の手順で行います.
① 仮説の設定
帰無仮説は「2群の母平均に差がない」,対立仮説は「2群の母平均に差がある」として設定します.
② 有意水準の決定
有意水準α=0.05または0.01として設定します.一般的にはα=0.05で設定されます.
③ 検定統計量の算出
T値を検定統計量として求めます.
④ p値の算出
検定統計量からp値を算出します.Excelではデータから直接p値を求めることができます.
⑤ 有意差判定
・p値<有意水準であれば,帰無仮説は棄却されて対立仮説を採択 → 「2群の母平均に差がある」
・p値\(\geq\)有意水準であれば,帰無仮説は棄却されない → 「2群の母平均に差があるとは言えない」
仮説検定の考え方や用語については,以下のページで解説しています.
t検定を行なうなら専用ソフトで!
統計アプリStaatAppを用いれば,Excelを用いるより簡単に対応のないt検定の検定統計量やp値,効果量を算出することができます.
t検定の結果を図示する際に用いられるエラーバーもマウス操作だけで,作成することができます.
初めての方はほぼ全ての機能を無料で利用できるので,お気軽にダウンロードしてお使いください!
》StaatAppで行う仮説検定
》統計解析アプリStaatApp

例題で用いるデータと仮説の設定
例題では以下のサンプルデータを用います.それぞれ異なる大学生10人の,授業Aと授業Bのテストの点数の結果になります.
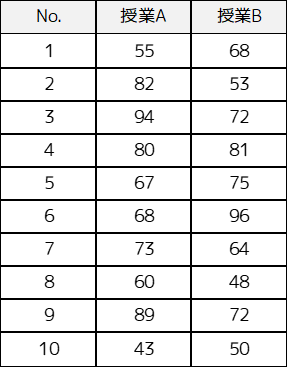
帰無仮説は「2つのテストの難易度(平均点数)に差がない」となり,対立仮説は「2つのテストの難易度(平均点数)に差がある」と設定します.
有意水準α=0.05で両側検定を行います.
Excelを用いたp値の計算(データ分析ツールの実行)
実際のExcel画面を用いてp値の計算手順を説明をします.利用しているExcelのバージョンはOffice2016になります.
対応のないt検定で使うツールを選択するために,「データ」タブの「データ分析」をクリックします.

出てきた「データ分析」ウィンドウから,「t検定: 等分散を仮定した2標本による検定」をクリックして「OK」を選択します.
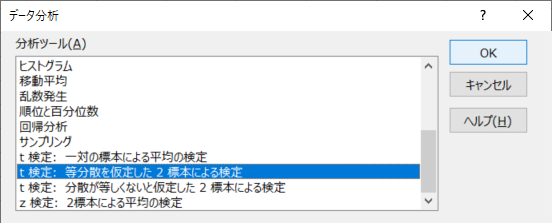
「t検定: 等分散を仮定した2標本による検定」では,入力する項目について説明します.
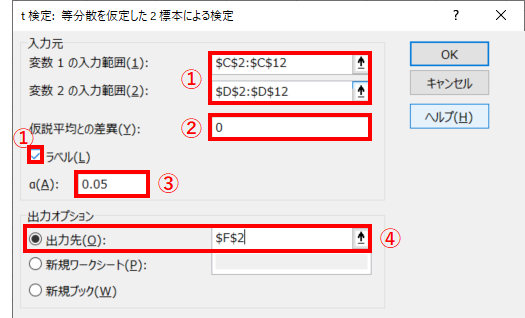
① 準備①で入力したデータのセルを選択します.データの範囲を選択する際に,ラベル(1行目の項目名)まで選択して「ラベル(L)」にチェックを入れます.
② 「仮説平均との差異(Y)」は”0”を入力します.
③ t検定の有意水準を入力します.有意水準α=0.05とする場合は,”0.05”を入力します.
④ 出力先は任意の場所を選択してください.同じシート内の空白のセルを選択すると出力結果が見やすいです.
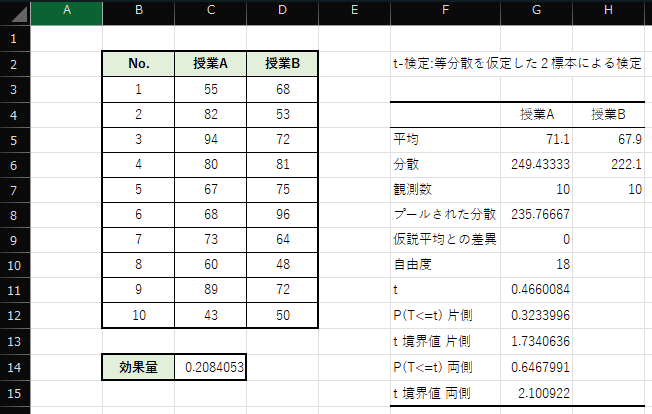
①から④までを入力して「OK」をクリックすると,出力指定したセルに以下の表が作成されます.
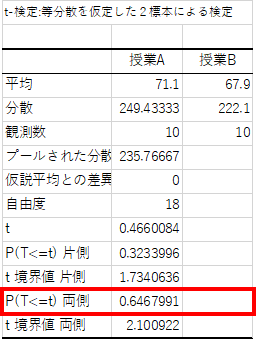
作成された表のうち,両側検定を行うので「P(T<=t) 両側」の行を見ます.これは,両側検定におけるp値を示しており,例題の結果は0.646..であることが分かります.
p値>有意水準α=0.05であるため2つのグループのデータに有意差は見られず,帰無仮説は棄却されません.よって「授業Aと授業Bのテストの難易度に差があるとは言えない」といった結論が得られます.
※ 表中の”t”は検定統計量,”t境界値 両側”は両側検定における限界値になります.
以上が,Excelを用いた対応のないt検定の手順になります.
補足① 片側検定の方法
片側検定の方法を解説します.
片側検定は,2つのグループの大小を明らかにしたい場合に行います.例題では帰無仮説は両側検定と同じ,「授業Aと授業Bのテストの難易度に差はない」とした際に,対立仮説は「授業Bのテストは授業Aのテストより難しい(=母平均が小さい)」とします.
片側検定において対立仮説を設定する場合は,予め2つのグループの平均値を比較することでどちらのグループの値が大きくまたは小さくなりそうかを予測しておきます. (統計学的にはデータを収集する段階から,明らかにしたい仮説を設定しておくべきです.)
分析ツールの実行方法・設定内容は両側検定と同じです.片側検定では出力された「P(T<=t) 片側」の行の結果を用います.
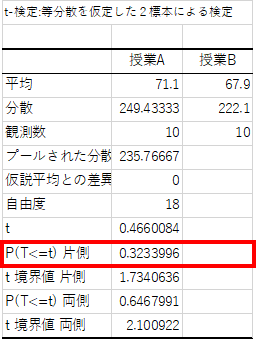
片側検定におけるp値は0.323..であり,有意差α=0.05より大きいことが分かります.よって帰無仮説を棄却できないことから,「授業Bのテストは授業Aのテストより難しいとは言うことはできない」 といった結論になります.
以上が片側検定の場合の手順になります.
補足② 効果量の求め方(Excel版)
仮説検定の結果として重要な効果量の求め方について,Excelを用いて解説します.
対応のないt検定の効果量は様々な方法で計算することができますが,ここではCohen’s dという効果量で解説します.
Statistical Power Analysis for the Behavioral Sciences by Jacob Cohen (1988)
Cohen’s dは以下の式で求めることができます.
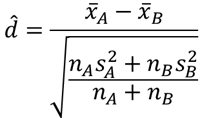
xA,xBは各グループの平均,nA,nBはサンプルサイズ,sA,sBは標本標準偏差になります.Excelではデータ分析ツールの結果を利用して以下のように求めることができます.
※ C14セルの入力式:=(G5-H5)/SQRT(((G7)G6+(H7)H6)/(G7+H7))
Cohen’s dは検定統計量であるt値を利用して以下の式でも簡単に求めることができます.
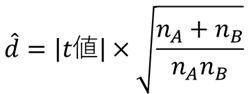
Cohen’s dの値の目安としては次のようになります.
【効果量dの目安】 小:0.2 中:0.5 大:0.8
例題において効果量は小さいため,授業Aと授業Bのテストの難易度にはそれほど差がないと言うことができます.
補足③ 用いるデータの前提条件
対応のないt検定を行う際に,用いるデータの前提条件について説明します.
① 対応のないグループ
対応のないt検定は対応のあるグループ(同一個体)のデータに対しては用いることができません.対応のある場合は,対応のあるt検定を行います.
② 正規分布に従う
t検定は,パラメトリックな検定になります.用いるデータが正規分布に従うと仮定できる場合に使うことができます.正規分布でない場合は,ノンパラメトリック検定であるマンホイットニーのU検定を行います.
③ 2つのグループの分散が等しい
比較する2つのグループの分散が等しい場合にt検定を行います.2つのグループの分散の検定はF検定で調べることができます.分散が等しくないときは,ウェルチのt検定を行います.
補足④ 打ち切りデータがある場合
データの観測期間内に結果が得られなかったり,追跡不能にとなったデータを統計学では打ち切りデータと言います.

検定を行う際に打ち切りデータを除いて行うことが多いですが,カプラン・マイヤー法などの生存時間解析を用いることで,打ち切りデータを含めた検定や多変量解析を行うことが可能です.





