



統計解析を行う上で注意すべきポイントを4つの観点で紹介します.
これから統計解析を行う方はもちろん,すでに分析行っている方は自分のやり方が正しいかのチェックシートとしても活用してみてください.
注意点 = 批判する観点にもなる
統計解析を行う上で注意しなければいけない点は,他人の研究・解析結果を批判するポイントにもなりえます.
他人の研究結果をこのページで紹介する観点で読むと,たくさん”ツッコミどころ”が見つかる場合もありますので,そういった気持ちでも読んでみてください.
データ収集段階での観点
統計学では”Garbage in, garbage out.”(ゴミを入れればゴミが出てくる)という名言があります.これはデータの質が悪い場合,どれだけ優れた分析を行っても意味のない結果しか生まれないと言った意味になります.
統計解析において扱うデータの質は非常に重要です.統計解析に慣れていない多くの方は,どのような手法を用いてどのような結果を示すかばかり重要視しがちです.しかし,データの収集方法はその調査・研究の質のほとんど決めてしまうといっても過言ではないほど重要です.
母集団・サンプリング・対照群の制御という観点から,データ収集前に注意すべき点を紹介します.
母集団
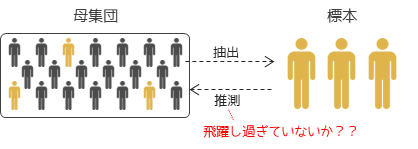
統計学では調べたい対象全体を母集団と言います.現実では母集団全てを調べることが難しいため,母集団から抽出したデータ(標本)で統計解析を行い母集団の特性を推測します(推測統計).
注意すべき点としては,標本から母集団を推測する際に飛躍した結論となっていないかです.統計解析で標本から推測できるのは抽出した元の母集団になります.例えば,ある授業の受講生を母集団として抽出を行い得られたデータから統計解析を行ったとします.そこで得られた結論を適用できるのは調査した授業の受講生のみというのが,厳密な考え方になります.ある授業の受講生を母集団をとして得られた平均睡眠時間を,日本人全体の平均睡眠時間として考えることには違和感を感じる人は多いと思います.
ただし慣習的に結論を異なる母集団にも適用することは多々あります.新薬に対する日本人から得られた治験データを,人種の近いアジア人(全人類の場合も)に対しても適用することはよくあります.分析者として異なる母集団に解析結果を適用する場合は,母集団の相違点や一般化が適切である理由を説明する必要があります.
結果を記載する際に,母集団の情報や得られた結論の限界を示すことは重要です.また,仮説の結論を得るために必要な母集団は何か,その分野の既往研究などから調べるようにしてください.
サンプリング
サンプリングとは母集団から標本を抽出する工程になります.サンプリング方法によって様々な系統誤差(バイアス)が発生して,批判の対象となります.
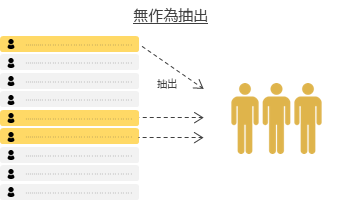
系統誤差を小さくする理想的なサンプリング方法は,無作為抽出になります.無作為抽出は母集団の要素のリストから,乱数を用いてランダムで調査対象を抽出する方法です.無作為抽出は母集団が小さい場合には可能ですが,母集団を日本人とした場合など大きい場合はリストの作成・調査が難しいです.
社会科学におけるほとんどの調査・研究で行われているサンプリング方法が,便宜抽出になります.
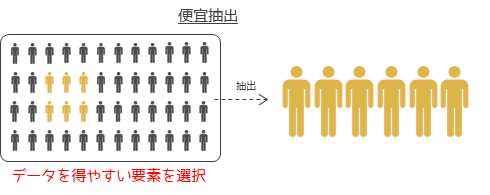
便宜抽出はデータを取得しやすい要素を選択して抽出する方法です.サンプリング方法を意識していない場合はほとんどが便宜抽出になり,例えば治験のためのバイト募集による抽出も便宜抽出です.便宜抽出ではサンプリングコストを大きく下げることができますが,様々な選択バイアスが生じることを意識してデータ分析を行う必要があります.
母集団と同様にサンプリング方法は結論の信頼性に大きく関わるため,結果を記載する際には必ず記述する必要があります.
対照群の制御
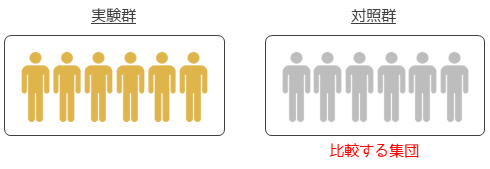
実験においてある効果を調べる場合は,よく対照群との比較を行います.実験群(処置群)に対しては調べたい効果が起きるように処置を行い,対照群には操作をしたと思わせるもしくは何もしないといった処置をします.
医学研究では治験を行う際に,対照群に対しては偽薬の投与を行います.しかし,偽薬を服用した被験者の中には投薬されたことに対する思い込みによって治験対象の薬と同じ効果が出る場合や,副作用が出る場合があります.このプラセボ効果は広く知られている事象なため,二重盲検法など効果を取り除く方法が確立されています.
医学研究以外の場合でも,対照群に属する被験者が観察されていることにより普段を違う行動を行う場合があります.例えば1週間の食生活のデータを集める場合に,被験者は調査されていることを意識して普段よりバランスの良い食事を取るなどです.このように調査対象からデータを収集する際に生じるバイアスを,情報バイアスと言います.
対照群は実験群に影響を与えている要因のみを取り除き,その他の条件は可能な限り等しくなるように努力する必要があります.
記述統計に対する観点
記述統計で用いる平均値は様々な場合で用いられる最も有名な統計量です.しかし,平均値及びその他の統計量が何を意味するかは十分に理解して使う,解釈する必要があります.
代表値
一般的に最も使われる統計量として,平均値があり安易に使われることが多いです.平均値は全てのデータの総和から求めるため,外れ値などがあるデータに対してはその集団の代表値として不適切な場合があります.
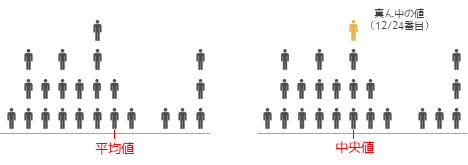
外れ値がある場合に集団の代表値として有効なのが中央値になります.中央値は各データの値に依らず,データ数(サンプルサイズ)の中心となるデータの値となります.上記のようにn=24の場合,12番目(12.5 or 13 番目の場合もある)データの値が中央値となります.
一定の基準から外れたデータを除外した,トリム平均という代表値も使われることがあります.2標準偏差以上や,母集団の上位もしくは下位10%といった基準がよく使われます.
ただし,外れ値を取り除いて分析を行う場合は,取り除く妥当性を説明する必要があります.
標準誤差
標準誤差(SE)は標本平均のばらつきを示す指標になります.論文などで複数の集団に対して平均を比較する場合には,必ず示すべき指標になります.
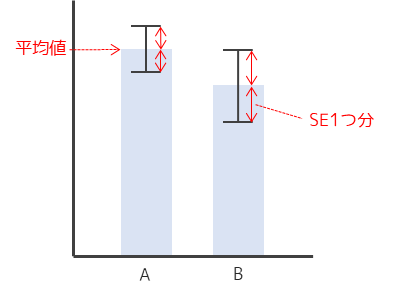
標準誤差は上記のように,平均値を示した棒グラフに対してエラーバーとして示されることが多いです.
グラフに対する観点
グラフはデータを図示することで,直感的な理解が容易になります.しかし,グラフの描き方によって誤った情報を伝えてしまう場合があります.
誤った使い方で特に多いのは,縦軸の操作になります.以下の棒グラフは同じデータに対して,縦軸を加工した場合と加工していない場合になります.
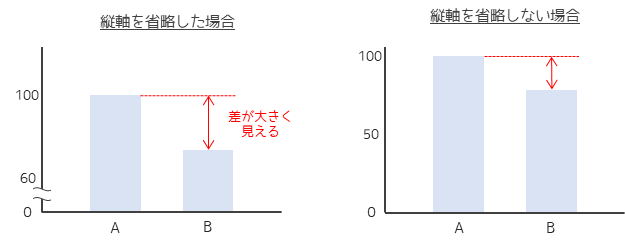
縦軸を省略したグラフは,省略していないグラフに比べて2つのグラフの差が大きく見えます.このように縦軸を省略することで,全体から見たら小さい差も大きく見せることができます.
敢えて差を大きく見せるために,縦軸を省略して使う人もいますが学術的観点では誤った棒グラフの使い方になります.
散布図の場合でも縦軸を操作することで,以下のように見え方を変えることができてしまいます.
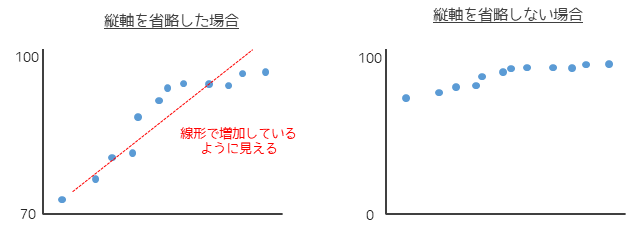
グラフを作る際のみ注意するのではなく,他人が作成したグラフを見る際にも縦軸が操作されていないかは注意する必要があります.
推測統計(分析手法)に対する観点
収集したデータに対して,要因の特定や予測を行うために様々な推測統計の手法を用います.解析手法ごとに注意すべき点は様々ですが,共通するのは前提条件と計算過程になります.
前提条件
統計学における解析手法には,扱うデータの前提条件が必ずあります.例えば仮説検定で最も使用される対応のないt検定では,以下の条件を満たす必要があります.
・独立した2つの標本
・母集団が正規分布に従うと仮定できる
・2つの標本が分散が等しい
上記の条件から著しく外れたデータに対して対応のあるt検定を行った場合は,誤った結果(第一種の過誤)を得る可能性が高まります.
回帰分析を行う場合は,扱うデータが数量データである必要があります.カテゴリーデータである場合に関係性を調べるためには,クラメールの連関係数や数量化Ⅱ類などデータに合わせて様々な手法が開発されています.
前提条件を間違えないためには,まず扱うデータの特性を調べることが重要です.最低限,統計学的なデータの種類や分布については把握してから,統計解析を行うようにしてください.
計算過程
統計解析を実際に計算する方法は様々です.有料の統計解析ソフトや統計解析用プログラミング言語のR,Excelなどの表計算ソフトを用いた方法などがあります.
StaatではExcelに計算式を入力して,統計解析を行う方法を紹介しています.ただし,論文など正式な解析結果として扱う場合は手計算ではなく有料ソフトや,統計解析用のプログラミング言語を用いて計算するようにしてください.
自分で計算式を作成する場合,計算を間違えるリスクがあるからです.有料ソフトやプログラミング言語のライブラリは,多くの人から検証が行われており計算精度が担保されています.
また,Excelを用いた場合同じ計算過程を別のデータに適用できない(行を追加するなど計算式の改変が必要)など,再現性がないというのも大きなデメリットになります.
Staatでは統計解析でよく用いられるPythonのライブラリを利用した,統計解析アプリStaatAppを販売しています.

理想と実務のギャップ
ここまで紹介した観点を満たした解析結果は,統計学において理想的な解析結果と言えます.しかし実務においてすべての観点を十分に満たすことは難しいです.特にデータ収集段階での観点を完全に満たせることはほとんどなく,母集団とサンプリング方法で最適なバランスを取る必要があります.
そもそも統計解析(特に推測統計)は母集団の全数調査が難しい場合に,効率的に仮説を検証するための手法になります.自分の仮説を検証するためには,何が最適で効率的かを考えることが統計学的な思考になります.
私の場合は統計解析を用いてよりよい成果を生むために,以下のことを心がけています.
・理想のデータを収集する努力
・データの収集方法や解析対象の情報,解析手法の明記
・正しい統計的手順の実行




